-
[카프카 핵심 가이드] CH6. 카프카 내부 메커니즘 - 물리적 저장소Study/카프카 핵심 가이드 2025. 3. 8. 00:04
6.5 물리적 저장소
- 카프카의 기본 저장 단위는 '파티션 레플리카'
- 하나의 파티션은 서로 다른 브로커들 사이에 분리될 수 없고, 같은 브로커의 서로 다른 디스크에 분할 저장될 수 없음
- 따라서 파티션의 크기는 특정 마운트 지점에 사용 가능한 공간의 제한을 받음
- 카프카를 설정할 때 운영자가 파티션들이 저장될 디렉토리 목록을 정의함
- log.dirs 매개변수에 지정
- 카프카가 사용할 각 마운트 지점별로 하나의 디렉토리를 포함하도록 설정하는 것이 일반적
추가) log.dirs
더보기log.dirs
- 카프카는 모든 메시지를 로그 세그먼트(log segment) 단위로 묶어 log.dir 설정에 지정된 디스크 디렉토리에 저장함
- 다수의 디렉토리를 지정하고자 할 때, log.dirs 사용하는 것이 좋음 (log.dirs가 설정되어 있지 않을 경우, log.dir이 사용됨)
- log.dirs는 쉼표로 구분된 로컬 시스템 경로의 목록
- 1개 이상의 경로가 지정되었을 경우, 브로커는 가장 적은 수의 파티션이 저장된 디렉토리에 새 파티션을 저장함
- 같은 파티션에 속하는 로그 세그먼트는 동일한 경로에 저장됨
- 사용된 디스크 용량 기준이 아닌 저장된 파티션 수 기준으로 새 파티션의 저장 위치를 배정한다는 점에 유의해야 함
- 이로 인해 다수의 디렉토리에 균등한 양의 데이터가 저장되지 않음 (파티션별 용량 차이 존재하니까)
6.5.1 계층화된 저장소
등장 배경
- 카프카를 대량의 데이터를 저장하기 위한 목적으로 사용하고자 함
- 이는 다음과 같은 문제를 야기함
- 파티션별로 저장 가능한 데이터에 한도가 존재한다.
- 최대 보존 기한과 파티션 수는 제품의 요구 조건이 아닌 물리적인 디스크 크기의 제한을 받을 수 있음
- 디스크와 클러스터 크기는 저장소 요구 조건에 의해 결정된다.
- 저장소 크기를 늘리는 것은 비용과 직결됨
- 파티션의 크기에 따라 클러스터의 탄력성이 좌우된다.
- 클러스터의 크기를 키우거나 줄일 때, 파티션의 위치를 다른 브로커로 옮기는 데 걸리는 시간은 파티션의 크기에 따라 결정됨
- 파티션의 크기가 클수록 클러스터의 탄력성을 줄어듦
- Q. 클러스터의 탄력성? A. 분산 데이터 저장소에서 노드를 추가하거나 제거하는 용이성
- 파티션별로 저장 가능한 데이터에 한도가 존재한다.
적용 (카프카 3.6부터 사용 가능)
- 계층화된 저장소 기능은 카프카 클러스터의 저장소를 로컬과 원격, 두 계층으로 나눔
- 로컬 계층 : 현재의 카프카 저장소 계층과 똑같이 로그 세그먼트를 저장하기 위해 카프카 브로커의 로컬 디스크 사용
- 원격 계층 : 완료된 로그 세그먼트를 저장하기 위해 HDFS(하둡 분산 파일 시스템)나 S3 같은 전용 저장소 시스템 사용
- 계층별로 서로 다른 보존 정책 설정 가능함
- 로컬 저장소가 리모트 계층 저장소에 비해 비싸므로 로컬 계층의 보존 기한은 짧게, 원격 계층의 보존 기한 더 길게 설정
- 로컬 저장소는 원격 저장소에 비해 지연이 훨씬 짧은 특징 고려
- 지연에 민감한 어플리케이션들은 로컬 계층에 저장되어 있는 최신 레코드를 읽어오도록 함
- 빠진 처리 결과를 메꾸는 작업이나 장애에서 복구되고 있는 어플리케이션들은 로컬 계층에 있는 것보다 더 오래된 데이터가 필요하므로 원격 계층에 있는 데이터가 전달됨
- 계층화된 저장소 기능의 이중화 구조로 카프카 클러스터의 메모리와 CPU에 상관없이 저장소 확장이 가능해짐
- 따라서 카프카는 장기간용 저장 솔루션으로서의 역할을 할 수 있게 됨
- 장점
- 카프카 브로커에 로컬 저장되는 데이터 양이 줄어, 복구와 리밸런싱 과정에서 복사되어야 할 데이터의 양 감소
- 원격 계층에 저장되는 로그 세그먼트들은 굳이 브로커로 복원될 필요 없이 원격 계층에서 바로 클라이언트로 전달
- 모든 데이터가 브로커에 저장되는 것이 아니므로 전체 데이터 보존 기한 또한 길게 잡아줄 수 있음
정리하면,
- 카프카 클러스터 내 카프카 브로커들의 로컬 저장공간 용량의 한계를 개선하기 위해 원격 저장공간 사용하도록 함
- 이러한 계층화된 저장소 기능으로 무한한 저장 공간, 더 낮은 비용, 탄력성 제공 및 오래된 데이터와 실시간 데이터를 읽는 작업 분리시킴
참고)
- https://cwiki.apache.org/confluence/display/KAFKA/KIP-405%3A+Kafka+Tiered+Storage
- https://developers.redhat.com/articles/2024/03/13/kafka-tiered-storage-deep-dive
6.5.2 파티션 할당
- 토픽을 생성하면, 파티션을 브로커 중 하나에 할당함
- 파티션을 할당할 때 목표는 다음과 같음
- 예시) 브로커 6개 존재, 파티션 10개 + 복제 팩터 3인 토픽 생성 --> 30개의 파티션 레플리카를 6개의 브로커에 할당하는 것
- 레플리카들을 가능한 한 브로커 간에 고르게 분산시킨다.
- 브로커별로 5개의 레플리카 할당해 줘야 함
- 각 파티션에 대해 각각의 레플리카는 서로 다른 브로커에 배치되도록 한다.
- 동일한 브로커에 리더와 팔로워가 배치되거나, 팔로워가 여러 개 배치될 수 없음
- 만약 브로커에 랙 정보가 설정되어 있다면, 가능한 한 각 파티션의 레플리카들을 서로 다른 랙에 할당한다.
- 카프카 버전 0.10.0 이상에서 가능
- 하나의 랙 전체가 작동 불가하더라도 파티션 전체가 사용 불가해지는 상황 방지 (랙 장애 발생 시에도 가용성 보장)
- Q. 파티션을 어느 브로커에 할당할까?
- 기본
- 임의의 브로커부터 시작해서 각 브로커에 라운드 로빈 방식으로 파티션 할당
- 1) 리더 레플리카 할당
- 리더 레플리카들이 각 브로커에 순차적으로 할당됨
- ex) 임의의 브로커가 4일 때
- 브로커가 6대
- 파티션 0의 리더 -> 브로커 4
- 파티션 1의 리더 -> 브로커 5
- 파티션 2의 리더 -> 브로커 0
- 2) 팔로워 레플리카 할당
- 각 파티션의 팔로워 레플리카는 리더로부터 증가하는 순서로 배치됨
- ex) 파티션 0의 리더가 브로커 4에 배치되었다면,
- 첫 번째 팔로워 -> 브로커 5
- 두 번째 팔로워 -> 브로커 0
- 1) 리더 레플리카 할당
- 임의의 브로커부터 시작해서 각 브로커에 라운드 로빈 방식으로 파티션 할당
- 브로커에 랙 정보 설정되어 있을 때
- 서로 다른 랙의 브로커가 번갈아 선택되도록 하여 파티션 할당
- ex) 랙1 : 브로커 0, 1 / 랙2 : 브로커 2, 3
- 파티션 0의 리더가 브로커 2에 할당된다면, 첫 번째 팔로워는 브로커 3이 아닌 다른 랙에 위치한 브로커 1에 할당
- 기본
- Q. 파티션을 브로커 내 어느 디렉토리에 저장할까?
- 각 파티션과 레플리카를 할당할 브로커 선택 후 새 파티션을 저장할 디렉토리를 결정함
- 파티션별로 독립적으로 수행
- 규칙
- 각 디렉토리에 저장되어 있는 파티션의 수 센 뒤, 가장 적은 파티션이 저장된 디렉토리에 새 파티션 저장
6.5.3 파일 관리 --> 세그먼트 관리(세그먼트는 하나의 데이터 파일 형태)
- 각 토픽에 대해 보존 기한(retention period)을 설정할 수 있음
- 삭제 단위는 파티션의 세그먼트
- 하나의 파티션을 여러 개의 세그먼트로 분할함
- 각 세그먼트는 1GB의 데이터 or 최근 1주일치의 데이터 중 적은 쪽만큼을 저장함
- 파티션 단위로 메시지를 쓰기 때문에 각 세그먼트 한도가 차면 세그먼트를 닫고 새 세그먼트를 생성함
- 현재 쓰여지고 있는 세그먼트를 '액티브 세그먼트(active segment)' 라고 함
- 액티브 세그먼트는 어떠한 경우에도 삭제되지 않음 (즉, 세그먼트가 닫히기 전까지는 데이터 삭제 불가)
- 참고) 카프카 브로커는 각 파티션의 모든 세그먼트에 대해 파일 핸들을 엶 (액티브 세그먼트를 포함한 모든 세그먼트 대상)
- 따라서 사용중인 파일 핸들 수가 매우 높게 유지될 수 있음
6.5.4 파일 형식 --> 세그먼트 형식(세그먼트는 하나의 데이터 파일 형태)
- 각 세그먼트는 하나의 데이터 파일 형태로 저장됨
- 파일 안에는 카프카의 메시지와 오프셋이 저장됨
- 특징
- 표준화된 binary message format 사용
- 디스크에 저장되는 데이터의 형식은 네트워크를 통해 전달되는 형식과 동일함
- 즉, 사용자가 프로듀서를 통해 브로커로 보내고, 나중에 브로커로부터 컨슈머로 보내지는 메시지의 형식과 동일함
- 데이터 형식 통일의 장점
- 카프카는 컨슈머에 메시지를 전송할 때 제로카피(zero-copy) 최적화를 달성할 수 있음
- 프로듀서가 이미 압축한 메시지들을 압축 해제한 후 다시 압축하지 않아도 됨
- Q. 메시지 형식을 변경하고자 한다면?
- 네트워크 프로토콜과 디스크 저장 형식이 모두 변경되어야 함 --> 카프카 프로듀서, 브로커, 컨슈머가 사용하는 메시지 형식이 모두 변경되어야 하는 것
- 카프카 브로커들은 업그레이드로 인해 2개의 파일 형식이 뒤섞여 있는 파일을 처리할 방법을 알아야 함
- 디스크에 저장되는 데이터의 형식은 네트워크를 통해 전달되는 형식과 동일함
- 메시지 배치 사용
- 카프카 버전 0.11(v2 메시지 형식)부터 카프카 프로듀서는 메시지를 배치 단위로 전송함
- 메시지 배치 헤더에 대부분의 시스템 정보가 저장됨
- 하나의 카프카 메시지는 사용자 페이로드, 시스템 헤더 두 부분으로 나뉘어짐
- 사용자 페이로드 : key, value, headers
- 각 메시지 역시 자체적인 시스템 헤더를 가지지만 대부분의 시스템 정보는 메시지 배치 헤더에 저장됨
- 하나의 카프카 메시지는 사용자 페이로드, 시스템 헤더 두 부분으로 나뉘어짐
- 표준화된 binary message format 사용
- 참고)
- 카프카 브로커에 포함되어 있는 DumpLogSegment 툴을 사용해 파일시스템에 저장된 파티션 세그먼트를 읽을 수 있음
- $ bin/kafka-run-class.sh kafka.tools.DumpLogSegments
- 카프카 브로커에 포함되어 있는 DumpLogSegment 툴을 사용해 파일시스템에 저장된 파티션 세그먼트를 읽을 수 있음
추가) 카프카 시스템의 비효율 및 해결방안 (위의 1, 2 방식을 사용하게 된 이유)
더보기1) 빈번한 작은 I/O 작업
- 방안 : 메시지 배치 사용
2) 과도한 byte copying
- 방안 : 표준화된 binary message format 제공
- 해당 메시지 형식을 카프카 브로커, 프로듀서, 컨슈머 모두 공유해서 사용하도록 함
- 브로커에서 메시지 저장, 전송 시 메시지 변환이 필요없어 zero-copy 달성할 수 있음
- 브로커 설정 파일의 log.message.format.version 값으로 설정 가능
- 주의)
- 카프카 프로듀서, 컨슈머가 사용하는 메시지 형식 버전 < 카프카 브로커의 버전이면, zero-copy 사용 불가
- 컨슈머에 메시지 전송하기 전 메시지 형식 변환하여 응답해야함 (Down Conversion)
- 브로커의 메시지 형식 버전 업그레이드 시에는 클라이언트들의 메시지 형식 버전도 함께 업그레이드 해야 함
- 카프카 프로듀서, 컨슈머가 사용하는 메시지 형식 버전 < 카프카 브로커의 버전이면, zero-copy 사용 불가
참고) https://kafka.apache.org/27/documentation.html#maximizingefficiency
6.5.5 인덱스
- 2가지의 인덱스 제공
- 1) 오프셋과 세그먼트 파일 및 그 안에서의 위치 매핑하는 인덱스
- 브로커가 요청한 오프셋의 메시지를 빠르게 찾을 수 있도록 하기 위함
- 2) 오프셋과 타임스탬프와 매핑하는 인덱스
- 타임스탬프 기준으로 메시지를 찾을 때 사용
- 1) 오프셋과 세그먼트 파일 및 그 안에서의 위치 매핑하는 인덱스
- 특징
- 인덱스 역시 세그먼트 단위로 분할됨
- 파티션의 메시지를 삭제할 때 오래된 인덱스 항목 역시 삭제할 수 있음
- 인덱스가 오염될 경우 해당하는 로그 세그먼트에 포함된 메시지들을 다시 읽어 오프셋과 위치를 기록하는 방식으로 재생성됨
- 인덱스 세그먼트를 삭제해도 자동으로 재생성됨
- 인덱스 역시 세그먼트 단위로 분할됨
6.5.6 압착 --> 토픽 단위로 설정
- 카프카는 두 가지 보존 정책 제공
- 삭제(delete) 정책
- 지정된 보존 기한보다 더 오래된 이벤트를 삭제함
- 압착(compact) 정책
- 토픽에서 각 키의 가장 최근값만 저장하도록 함
- 토픽에 키 값이 null인 메시지가 있을 경우 압착은 실패함
- 사례)
- 고객의 배송지 주소를 저장할 때
- 삭제 정책 적용하여 지난 1주일 동안, 혹은 1년 동안의 변경 내역의 데이터를 저장하는 것보다 가장 마지막의 것만 저장하는 것이 더 합리적임
- 어플리케이션의 현재 상태를 저장할 때
- 크래시가 발생한 뒤 복구 과정에서 어플리케이션은 이 메시지를 카프카에서 읽어와 최근 상태를 복원함
- 이때 중요한 것은 크래시 나기 직전의 마지막 상태임
- 고객의 배송지 주소를 저장할 때
- 삭제(delete) 정책
- 두 가지 정책 동시에 적용 가능
- 보존 기한과 압착 설정 동시에 가능함
- 지정된 보존 기한보다 오래된 메시지들은 키에 대한 최근 값인 경우에도 삭제될 것임
6.5.7 압착의 작동 원리 --> 세그먼트 단위로 수행
- 파티션 로그는 다음과 같이 두 영역으로 나누어짐
- 클린(Clean)
- 이전에 압착된 적이 있었던 메시지들이 저장됨
- 하나의 키마다 하나의 값만을 포함하고 있음 (이전 압착 작업 시점에서의 최신값들)
- 더티(Dirty)
- 마지막 압착 작업 이후 쓰여진 메시지들이 저장됨
- 클린(Clean)

압착 수행 여부
- 압착 기능이 활성화되어 있을 경우(log.cleaner.enabled=true) 각 브로커는 압착 매니저 스레드와 함께 다수의 압착 스레드를 시작함 (해당 스레드들이 압착 작업 담당)
- 각 스레드는 전체 파티션 크기 대비 더티 메시지의 비율이 가장 높은 파티션을 골라 압착한 뒤 클린 상태로 만듦
압착 과정
1. 압착할 세그먼트들 선정
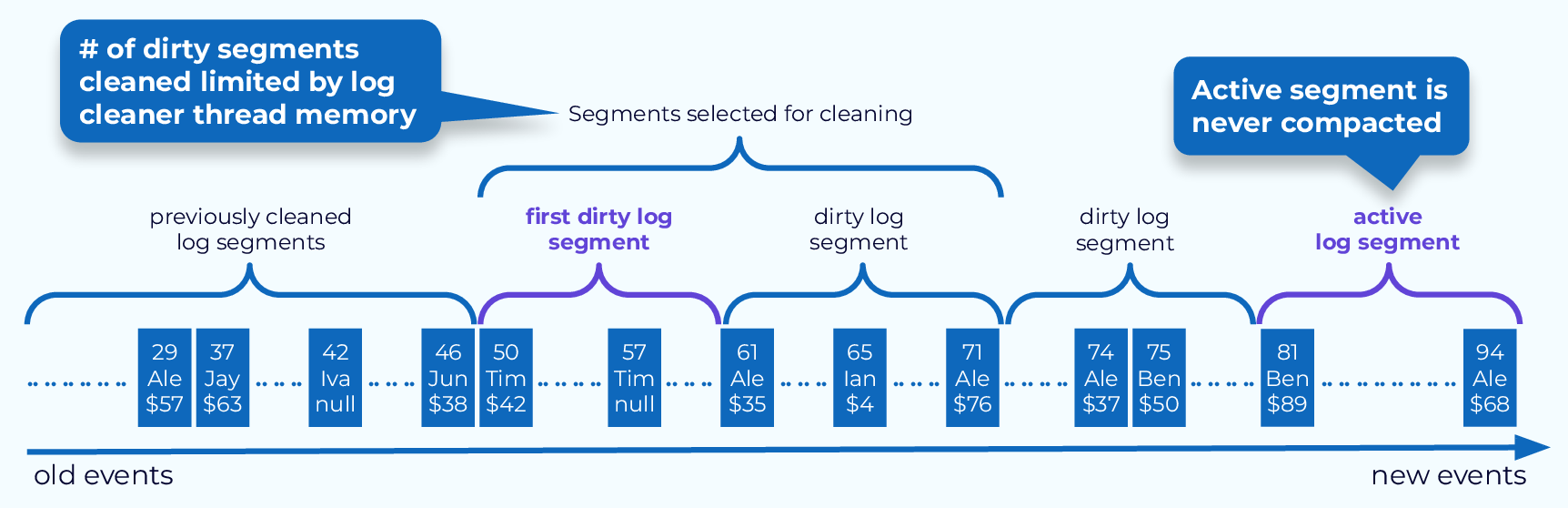
2. 선정된 세그먼트들 대상으로 인-메모리 맵 생성
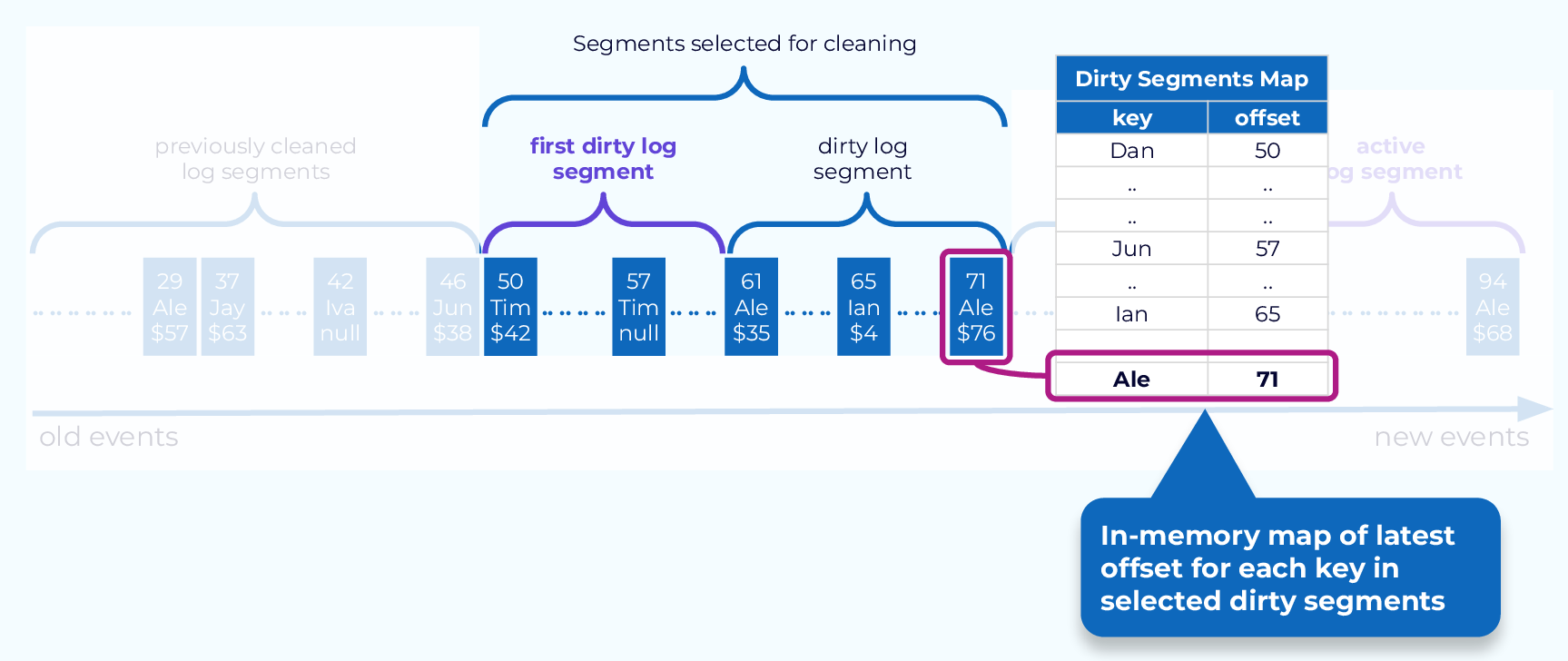
- 맵의 각 항목은 약 24바이트 사용함 (key : 16byte, offset : 8byte)
- 참고)
- 압착 스레드가 해당 맵을 저장하기 위해 사용할 수 있는 메모리의 양을 직접 설정도 가능함
- 스레드마다 개별 맵을 생성하기는 하지만, 해당 설정은 전체 스레드가 사용할 수 있는 메모리의 총량을 의미함
- 압착은 세그먼트 단위로 수행되므로 최소한 하나의 세그먼트 전체가 들어갈 수 있어야 함
- 그렇지 않을 경우 카프카는 에러 메시지 로깅함
3. 메시지 삭제 및 보류
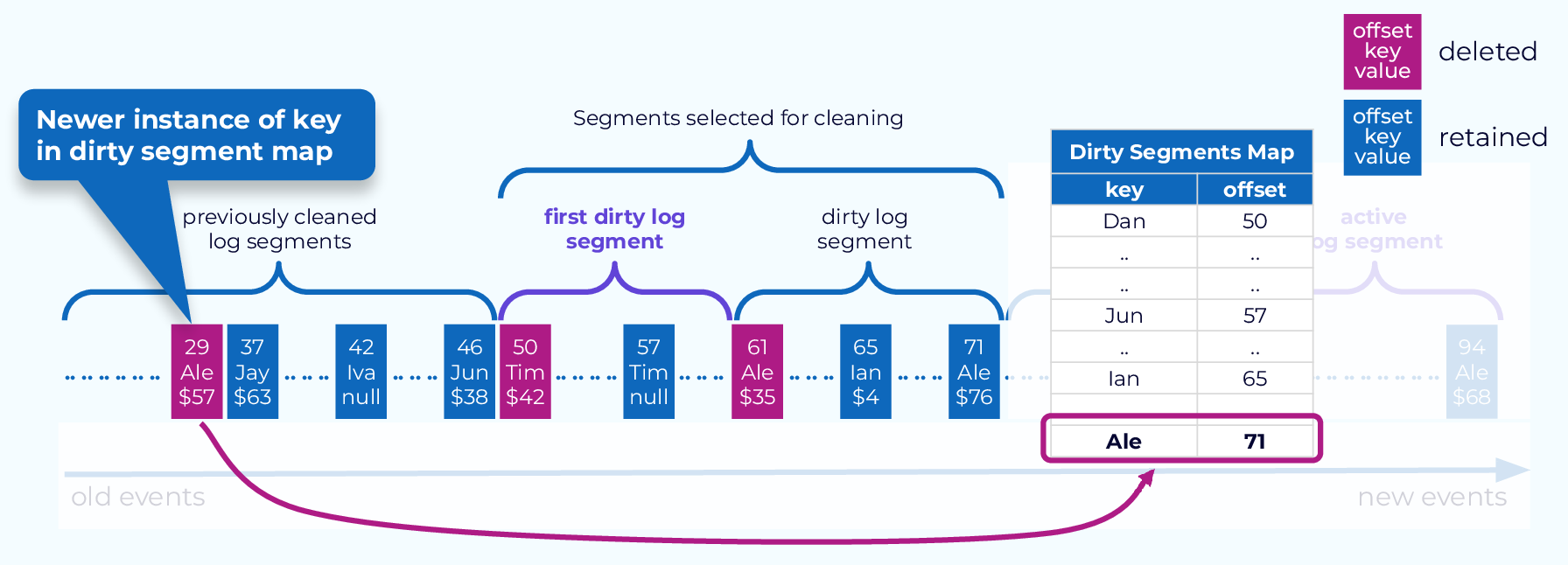
- 클린 세그먼트 내 각각의 메시지에 대해, 해당 메시지의 키값이 현재 오프셋 맵에 저장되어 있는지 확인함
- 저장되어 있다면 삭제 대상, 저장되어 있지 않다면 보류 대상
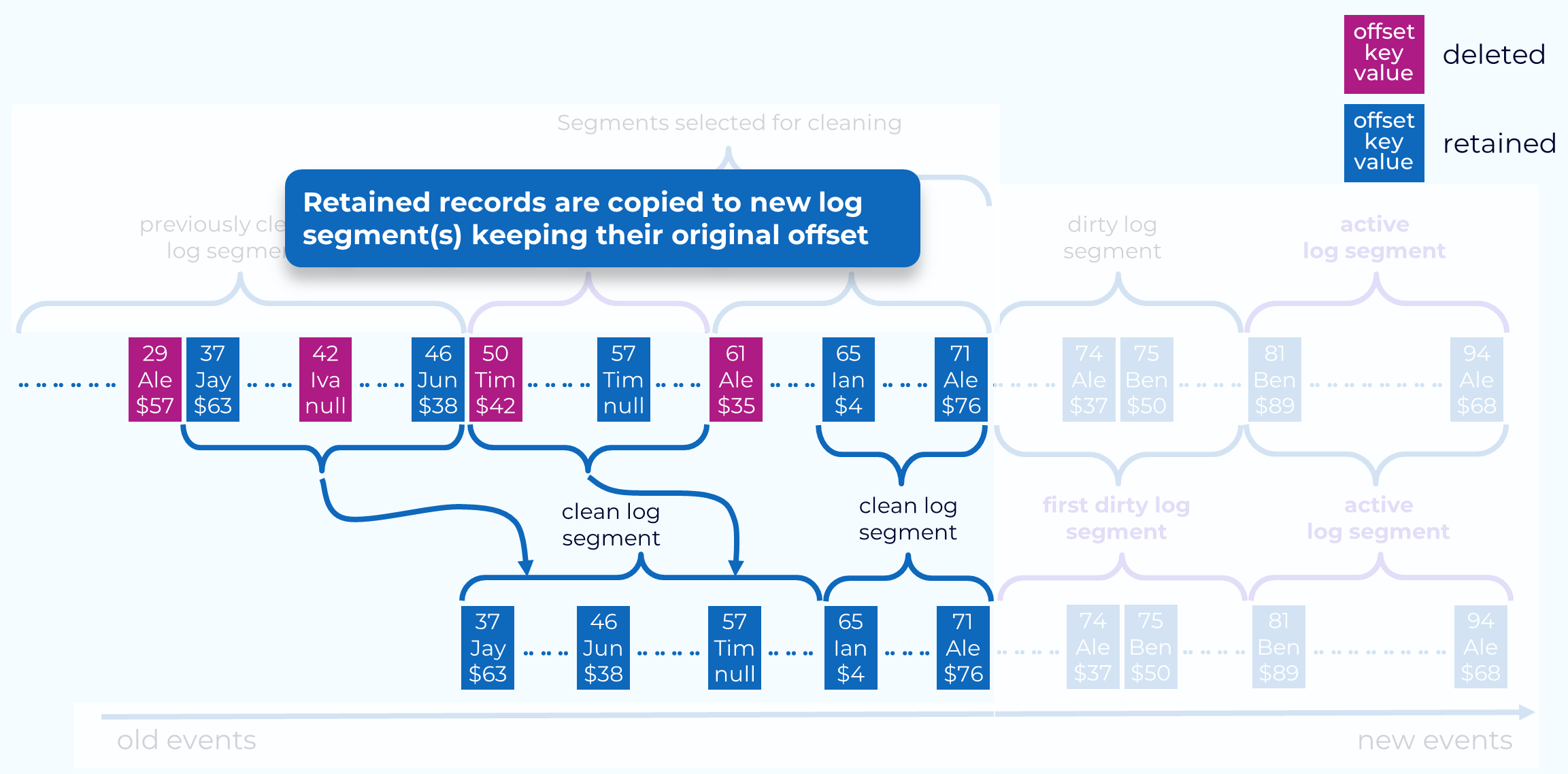
- 보류 대상 메시지들만 교체용 세그먼트로 복사됨
4. 세그먼트 교체
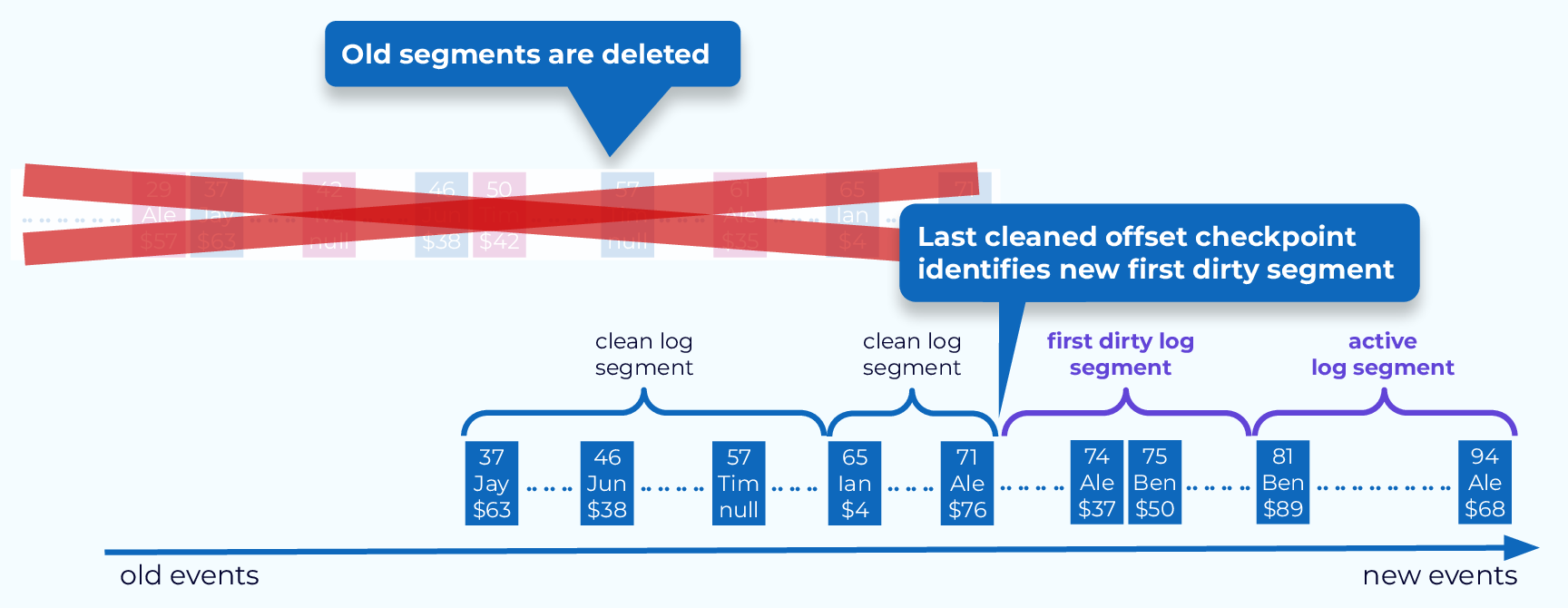
- 메시지 복사가 완료되면, 압착 스레드는 교체용 세그먼트와 원본 세그먼트를 바꾼 뒤 다음 더티 세그먼트를 대상으로 압착을 계속 진행함
- 작업이 완료되면, key별로 (최신 value값을 포함하는) 하나의 메시지만 남게 됨
cf) https://developer.confluent.io/courses/architecture/compaction/
6.5.8 삭제된 이벤트
상황1) 특정 키를 갖는 모든 메시지를 삭제하고 싶을 때
- 토픽의 압착 기능 사용
- 방식
- key: 삭제하고자 하는 키 값, value: null을 갖는 메시지를 발행함
- 클리너 스레드가 이 메시지를 발견하면 평소대로 압착 작업을 한 뒤 value: null 값을 가진 메시지만 보존하게 됨
- 카프카는 설정된 기간동안 해당 메시지를 보존하게 됨 (이러한 메시지를 'tombstone'이라고 함)
- 이 기간 동안, 컨슈머는 해당 메시지를 보고 해당 값이 삭제되었음을 알 수 있음
- 보존 기간 이후 클리너 스레드는 메시지를 삭제하며, 해당 키 역시 카프카 파티션에서 완전히 삭제되게 됨
- 예시) 사용자가 서비스를 탈퇴해서 해당 사용자의 모든 흔적을 시스템에서 지워야하는 경우
상황2) 지정된 오프셋 이전의 모든 레코드를 삭제할 때
- 카프카 어드민 클라이언트의 deleteRecords 메서드 사용 (지정된 오프셋 이전의 모든 레코드를 삭제함)
- 방식
- 해당 메서드를 호출하면, 카프카는 파티션의 첫 번째 레코드를 가리키는 로우 워터마크(low-water mark)를 해당 오프셋으로 이동시킴
- 컨슈머는 업데이트된 로우 워터마크 이전 메시지들을 읽을 수 없게 되므로 접근 불가능하게 됨
- 해당 레코드들은 나중에 클리너 스레드에 의해 실제로 삭제됨
6.5.9 토픽은 언제 압착되는가?
- 대상
- 삭제 정책과 마찬가지로 압착 정책 역시 현재의 액티브 세그먼트를 절대 압착하지 않음
- 액티브 세그먼트가 아닌 세그먼트에 저장되어 있는 메시지만이 압착의 대상이 됨
- 시점
- 기본적으로, 카프카는 토픽 내용물의 50% 이상이 더티 레코드인 경우에만 압착을 시작함
- 압착 기능의 목표는
- 토픽을 자주 압착하지 않으면서(압착은 토픽의 읽기/쓰기 성능에 영향을 줄 수 있음),
- 너무 많은 더티 레코드가 존재하지 않도록 하는 것(디스크 공간 낭비 줄이기 위함)
- 압착 기능의 목표는
- 아래 두 개의 설정 매개변수를 사용해 압착이 시작되는 시점을 조절할 수 있음
- min.compaction.lag.ms
- 메시지가 쓰여진 뒤 압착될 때까지 지나가야 하는 최소 시간 지정 (해당 시간 이후부터 압착 가능)
- max.compaction.lag.ms
- 메시지가 쓰여진 뒤 압착이 가능해질 때까지 딜레이 될 수 있는 최대 시간 지정
- 특정 기한 안에 압착이 반드시 실행된다는 것을 보장해야 하는 상황에 자주 사용됨
- min.compaction.lag.ms
- 기본적으로, 카프카는 토픽 내용물의 50% 이상이 더티 레코드인 경우에만 압착을 시작함
'Study > 카프카 핵심 가이드' 카테고리의 다른 글
[카프카] 카프카는 어떻게 고성능을 유지할까? (0) 2025.03.24 [카프카 핵심 가이드] CH7. 신뢰성 있는 데이터 전달 (0) 2025.03.09 [카프카 핵심 가이드] CH6. 카프카 내부 메커니즘 (0) 2025.02.19 [카프카 핵심 가이드] CH4. 카프카 컨슈머: 카프카에서 데이터 읽기 (2) (1) 2025.02.13 [카프카 핵심 가이드] CH4. 카프카 컨슈머: 카프카에서 데이터 읽기 (1) (0) 2025.02.11 - 카프카의 기본 저장 단위는 '파티션 레플리카'