-
[카프카 핵심 가이드] CH4. 카프카 컨슈머: 카프카에서 데이터 읽기 (1)Study/카프카 핵심 가이드 2025. 2. 11. 21:24
4.1 카프카 컨슈머: 개념
4.1.1 컨슈머와 컨슈머 그룹
- 토픽의 메시지를 처리하기 위해서는 KafkaConsumer 객체를 생성하고, 대상 토픽을 구독하고, 메시지를 수신하여 처리해야 한다.
- 카프카 컨슈머는 컨슈머 그룹의 일부로서 동작한다.
- 각각의 컨슈머는 동일한 토픽에서 서로 다른 파티션을 할당받아 파티션의 메시지를 처리함
- 따라서 컨슈머 그룹에 컨슈머를 추가하는 것은 카프카 토픽에서 읽어오는 데이터 양을 확장하는 주된 방법이다.
- 컨슈머를 추가하여 단위 컨슈머가 처리하는 파티션과 메시지의 수를 분산시키는 것이 일반적인 규모 확장 방식
- 정리하자면,
- 1개 이상의 토픽에 대해 모든 메시지를 받아야 하는 서비스별로 새로운 컨슈머 그룹을 생성한다.
- 컨슈머 그룹에 컨슈머를 추가하여 토픽에서 메시지를 읽거나 처리하는 규모를 확장할 수 있다.
4.1.2 컨슈머 그룹과 파티션 리밸런스
- 컨슈머에 할당된 파티션을 다른 컨슈머에게 할당해주는 작업을 '리밸런스(rebalance)'라고 함
- 참고) https://fordevelop.tistory.com/241
리밸런스 방식
요약
- Eager Rebalance : 모든 파티션을 한 번에 반납 후 재할당, 컨슈머 그룹 내 모든 컨슈머의 데이터 소비 중단 발생
- Cooperative Rebalance : 일부 파티션만 반납 후 점진적으로 재할당, 특정 파티션에 대해서만 데이터 처리 중단 발생
방식1) 조급한 리밸런스 (Eager Rebalance)
- 방식
- 컨슈머 그룹 내 모든 컨슈머는 읽기 작업을 멈추고 자신에게 할당된 모든 파티션에 대한 소유권을 포기함
- 이후 컨슈머 그룹에 다시 참여하여 완전히 새로운 파티션 할당을 전달받음
- 컨슈머의 읽기 작업이 중단되는 시간의 길이는 컨슈머 그룹의 크기 및 여러 설정 매개 변수의 영향을 받는다.
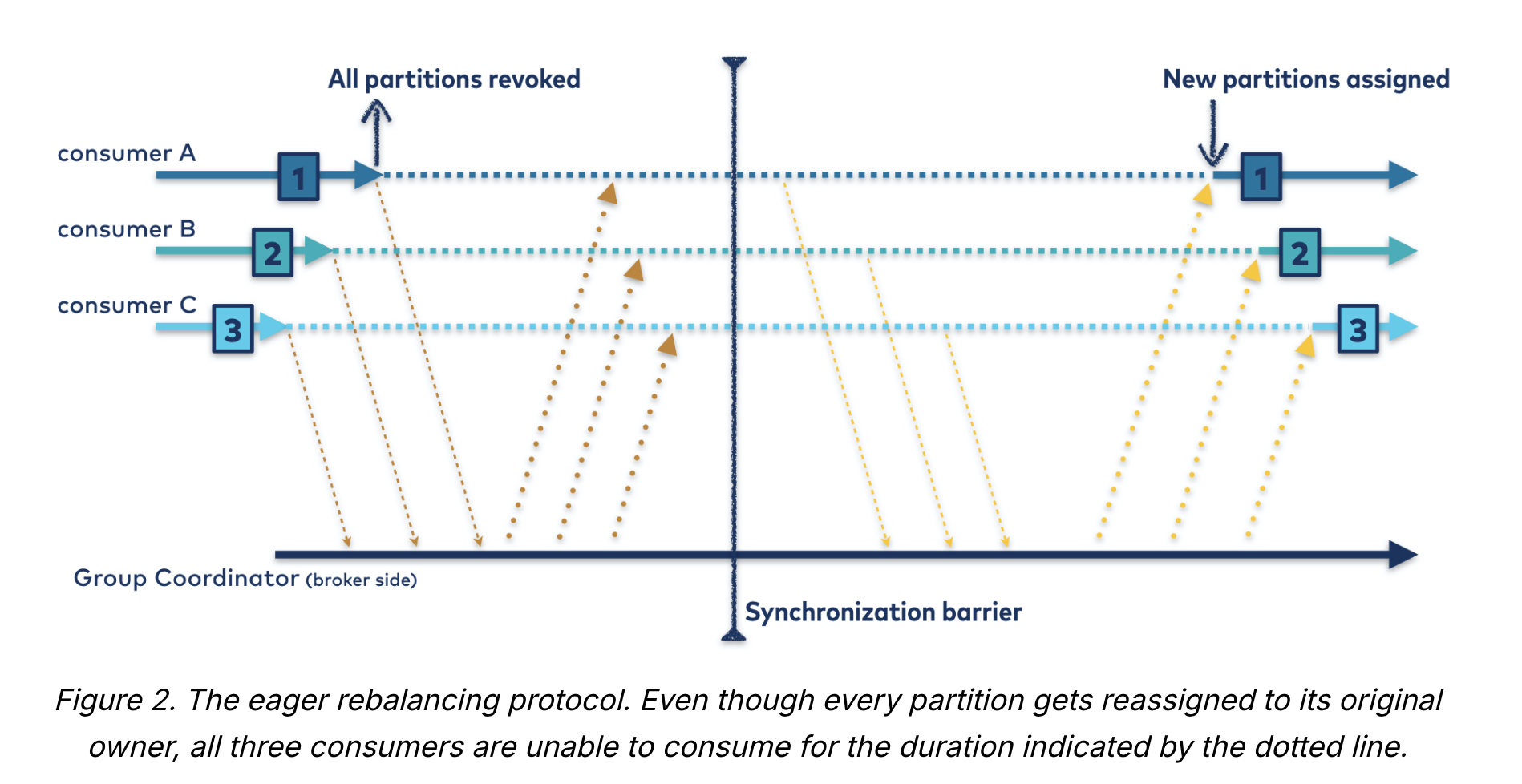
- 조급한 리밸런스는 두 단계에 걸쳐 일어남
- 1) 모든 컨슈머가 자신에게 할당된 파티션 포기, 2) 컨슈머가 다시 컨슈머 그룹에 참여하여 새로운 파티션 할당받아 읽기 작업 재개
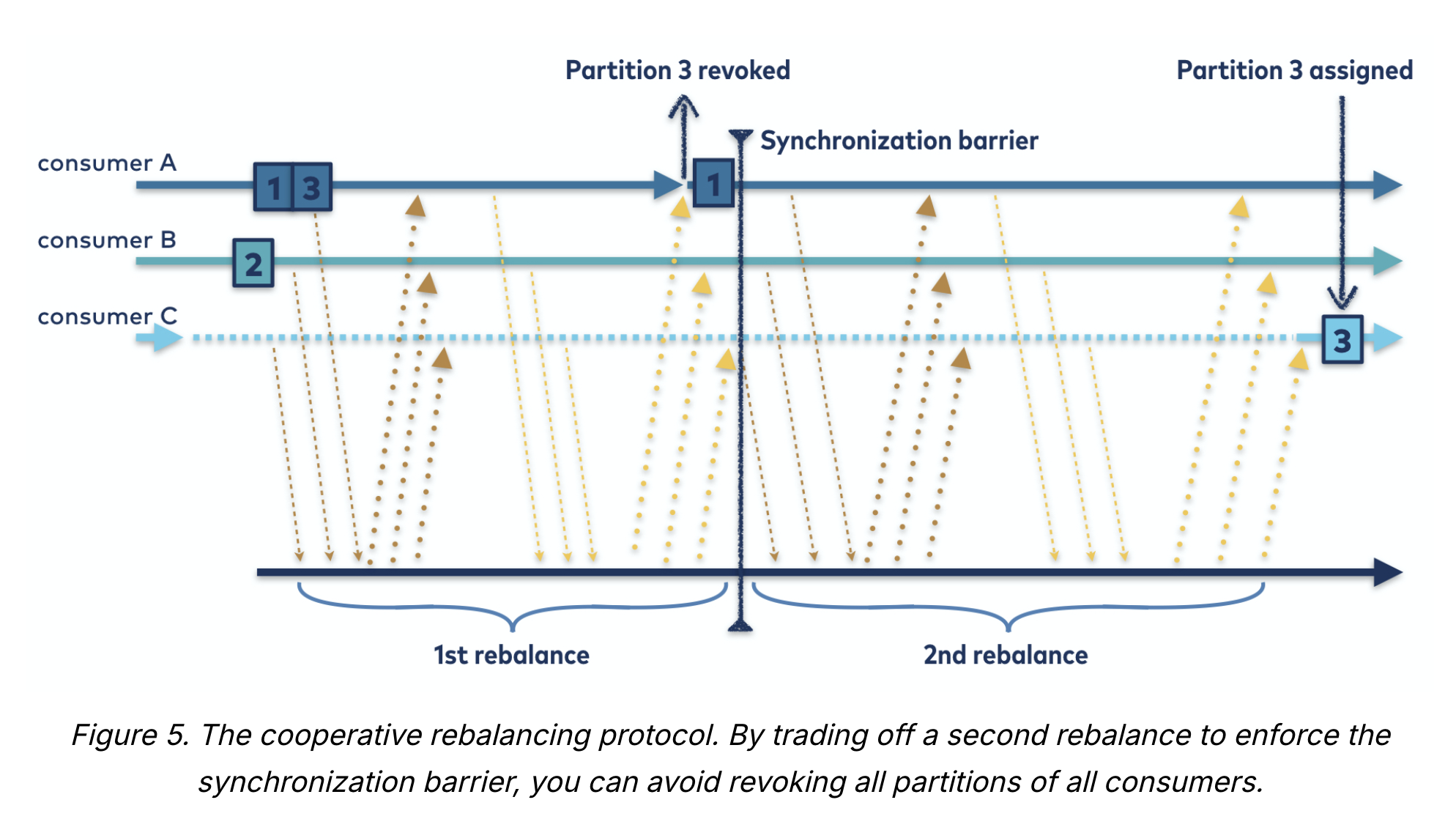
방식2) 협력적 리밸런스 (Cooperative Rebalance) -> 카프카 버전 3.1부터 기본값
- 방식
- 한 컨슈머에게 할당되어 있던 파티션만을 다른 컨슈머에 재할당함
- 재할당되지 않은 파티션을 담당하는 컨슈머들은 처리를 계속할 수 있음
- 리밸런싱은 2개 이상의 단계에 걸쳐 수행됨
- 1) 컨슈머 그룹 리더가 다른 컨슈머들에게 각자에게 할당된 파티션 중 일부가 재할당될 것이라고 통보하면, 컨슈머들은 해당 파티션에서 데이터를 읽어오는 작업을 멈추고 해당 파티션에 대한 소유권 포기함
- 2) 컨슈머 그룹 리더가 포기된 파티션들을 새로 할당함
- 안정적으로 파티션이 할당될 때까지 위 단계를 반복함
- Eager Rebalance에서 발생하는 전체 작업 중단은 발생하지 않음
- 리밸런싱 작업에 상당한 시간이 걸릴 위험이 있는 경우(컨슈머 그룹에 속한 컨슈머 수가 많은 경우)에 특히 중요함
- 한 컨슈머에게 할당되어 있던 파티션만을 다른 컨슈머에 재할당함
리밸런스 실행 기준
- 컨슈머는 해당 컨슈머 그룹의 그룹 코디네이터 역할을 지정받은 카프카 브로커에 heartbeat를 전송해 멤버십과 할당된 파티션에 대한 소유권을 유지함
- 그룹 코디네이터 담당 카프카 브로커는 컨슈머 그룹별로 다를 수 있음
- heartbeat는 컨슈머의 백그라운드 스레드에 의해 전송되고, 일정한 간격을 두고 전송되는 한 연결이 유지되고 있는 것으로 간주함
- Case
- 컨슈머가 비정상적으로 종료되었을 때 (컨슈머가 일정 시간 이상 heartbeat를 전송하지 않았을 때)
- 세션 타임아웃이 발생하고 그룹 코디네이터는 해당 컨슈머가 죽었다고 간주하고 리밸런스 수행함
- 몇 초 동안 죽은 컨슈머에 할당되어 있던 파티션에서는 아무 메시지도 처리되지 않음
- 컨슈머가 정상적으로 종료되었을 때
- 컨슈머가 그룹 코디네이터에게 그룹을 나간다고 통지하면, 그룹 코디네이터는 즉시 리밸런스를 실행하여 처리가 정지되는 시간을 줄임
- 컨슈머가 비정상적으로 종료되었을 때 (컨슈머가 일정 시간 이상 heartbeat를 전송하지 않았을 때)
추가) 파티션은 어떻게 컨슈머에게 할당될까?
- 파티션 할당 결정 --> 그룹 리더 담당
- 컨슈머가 그룹에 참여하고 싶을 때 그룹 코디네이터에게 JoinGroup 요청을 보냄
- 가장 먼저 그룹에 참여한 컨슈머가 그룹 리더가 됨
- 그룹 리더는 그룹 코디네이터로부터 해당 그룹 안에 있는 모든 살아있는 컨슈머 목록을 받아 각 컨슈머에게 파티션의 일부를 할당해줌
- PartitionAssignor 인터페이스의 구현체가 사용됨
- 카프카는 몇 개의 파티션 할당 정책이 기본적으로 내장되어 있음
- 파티션 할당 전파 --> 그룹 코디네이터 담당
- 파티션 할당이 결정되는 컨슈머의 그룹 리더는 할당 내역을 그룹 코디네이터에게 전달하고, 그룹 코디네이터는 이 정보를 모든 컨슈머에게 전파함
- 각 컨슈머 입장에서는 자기에게 할당된 내역만 보임
- 즉, 클라이언트 프로세스 중 그룹 리더만 유일하게 그룹 내 컨슈머와 할당 내역 전부를 볼 수 있는 것
- 파티션 할당이 결정되는 컨슈머의 그룹 리더는 할당 내역을 그룹 코디네이터에게 전달하고, 그룹 코디네이터는 이 정보를 모든 컨슈머에게 전파함
- 이 과정은 리밸런스가 발생할 때마다 반복적으로 수행됨
4.1.3 정적 그룹 멤버십
- 기본적으로, 컨슈머가 갖는 컨슈머 그룹의 멤버로서의 자격(멤버십)은 일시적
- 컨슈머가 컨슈머 그룹을 떠나는 순간 해당 컨슈머에 할당되어 있던 파티션들은 해제되고, 다시 참여하면 새로운 멤버 ID가 발급되며 리밸런스 프로토콜에 의해 새로운 파티션들이 할당됨
멤버십 유지하는 방법
- group.instance.id를 사용해 컨슈머가 컨슈머 그룹의 정적인 멤버가 되도록 설정
- 같은 컨슈머 그룹 내에서 해당 값은 고유해야 함 (동일한 ID로 컨슈머 그룹 조인 요청 시 이미 존재한다는 에러 발생)
- 방식
- 컨슈머 그룹에 처음 참여했을 때
- 컨슈머가 정적 멤버로서 컨슈머 그룹에 처음 참여하면 평소와 동일하게 해당 그룹이 사용하고 있는 파티션 할당 전략에 따라 파티션이 할당됨
- 컨슈머가 죽었을 때
- 자동으로 컨슈머 그룹을 떠나지 않음
- session.timout.ms가 경과될 때까지 그룹 멤버로 남아있게 됨
- 해당 값은 어플리케이션 재시작 시간을 고려하되 너무 오랫동안 파티션 처리가 멈추지 않도록 해야 함
- session.timout.ms가 경과될 때까지 그룹 멤버로 남아있게 됨
- 자동으로 컨슈머 그룹을 떠나지 않음
- 컨슈머가 다시 그룹에 조인했을 때
- 멤버십이 그대로 유지되어 리밸런스 발생하지 않고 예전에 할당받았던 파티션들을 그대로 재할당받음
- 그룹 코디네이터가 그룹 내 각 멤버에 대한 파티션 할당을 캐싱해두기 때문에 리밸런스 없이 재할당 가능
- 멤버십이 그대로 유지되어 리밸런스 발생하지 않고 예전에 할당받았던 파티션들을 그대로 재할당받음
- 컨슈머 그룹에 처음 참여했을 때
언제 사용하면 좋을까?
- 어플리케이션이 각 컨슈머에 할당된 파티션의 메시지를 사용해 로컬 상태나 캐시를 유지해야 할 때 편리함
- 캐시 재생성이 오래 걸릴 경우 유용
- 고려할 점
- 정지되었던 컨슈머가 다시 돌아오면 재할당받은 파티션의 밀린 메시지부터 처리하게 됨
- 따라서 컨슈머가 재시작했을 때 밀린 메시지들을 따라잡을 수 있는지 확인할 필요 있음
4.2, 4.3 컨슈머 실행
- 컨슈머 실행을 위해 KafkaConsumer 객체 생성 -> 토픽 구독 -> 폴링 루프 단계가 존재한다.
4.4 폴링 루프
- 제공 기능
- 데이터 조회 외에도 많은 일을 수행함
- 새 컨슈머에서 처음으로 poll() 호출 시 컨슈머는 그룹 코디네이터를 찾아 컨슈머 그룹에 참가하고, 파티션을 할당받음
- 리밸런스도 연관된 콜백들과 함께 여기서 수행됨
- 즉, 컨슈머 혹은 콜백에서의 거의 모든 예외는 poll()에서 예외 발생되는 것
- poll()이 max.poll.interval.ms에 지정된 시간 이상으로 호출되지 않을 경우, 컨슈머는 죽은 것으로 판정되어 컨슈머 그룹에서 퇴출됨
- 폴링 루프 안에서 예측 불가능한 시간 동안 블록되는 작업 수행 피해야 함
4.4.1 스레드 안정성
- 하나의 스레드당 하나의 컨슈머가 원칙!
- 하나의 스레드에서 동일한 그룹 내에 여러 개의 컨슈머 생성 불가
- 같은 컨슈머를 다수의 스레드에서 안전하게 사용 불가
- 하나의 어플리케이션에서 동일한 그룹에 속하는 여러 개의 컨슈머를 실행하고 싶다면 스레드를 여러 개 띄워 스레드당 1개의 컨슈머를 실행해야 함
- 또 다른 방법으로는 이벤트를 받아 큐에 넣는 컨슈머 하나와 이 큐에서 이벤트를 꺼내 처리하는 여러 개의 워커 스레드를 사용하는 것
4.5 컨슈머 설정하기
4.5.1 fetch.min.bytes
- 컨슈머가 브로커로부터 레코드를 얻어올 때 받는 데이터의 최소량(바이트) 지정 (기본값 1byte)
- 만약 브로커가 컨슈머로부터 레코드 요청을 받았는데 새로 보낼 레코드의 양이 fetch.min.bytes보다 작을 경우, 브로커는 충분한 메시지를 보낼 수 있을 때까지 기다림
- 해당 값을 증가시킬 경우 처리량이 적은 상황에서 메시지 처리 지연이 증가할 수 있음 주의
4.5.2 fetch.max.await.ms
- 컨슈머가 브로커로부터 fetch.min.bytes 크기의 레코드를 얻기 위해 기다리는 최대 시간 지정 (기본값 500ms)
- 카프카는 컨슈머에게 리턴할 데이터가 부족할 경우 리턴할 데이터 최소량 조건을 맞추기 위해 기본 500ms 기다림
- 예시) fetch.min.bytes = 1MB, fetch.max.await.ms = 100ms
- 카프카는 컨슈머로부터 읽기(fetch) 요청을 받았을 때 리턴할 데이터가 1MB 이상 모이거나 100ms가 지나거나, 두 조건 중 하나가 만족되면 컨슈머에게 리턴함
4.5.3 fetch.max.bytes
- 컨슈머가 브로커를 폴링할 때 카프카가 리턴하는 최대 바이트 수 지정 (기본값 50MB)
- 컨슈머가 서버로부터 받은 데이터를 저장하기 위해 사용하는 메모리의 양을 제한하기 위해 사용함
- 얼마나 많은 파티션으로부터 얼마나 많은 메시지를 받았는지와는 무관!
- 참고) 브로커가 컨슈머에 레코드를 보낼 때 배치 단위로 전송하고, 만약 브로커가 보내야 하는 첫 번째 레코드 배치의 크기가 해당 설정값을 넘길 경우, 제한값을 무시하고 해당 배치를 그대로 전송함
- 컨슈머가 읽기 작업을 계속해서 진행할 수 있도록 보장해줌
- 참고) 브로커 설정에도 최대 읽기 크기를 제한하는 설정 존재함
- 대량의 데이터에 대한 요청은 대량의 디스크 읽기와 오랜 네트워크 전송 시간을 초래하여 카프카 브로커 부하를 증가시킬 수 있기 때문에 이를 방지하기 위함
4.5.4 max.poll.records
- poll()을 호출할 때마다 리턴되는 최대 레코드 수 지정
- 어플리케이션이 폴링 루프를 반복할 때마다 처리해야 하는 레코드의 개수 제어할 때 사용
4.5.5 max.partition.fetch.bytes
- 카프카 브로커가 파티션별로 리턴하는 최대 바이트 수 지정 (기본값 1MB)
- KafkaConsumer.poll()이 ConsumerRecords를 리턴할 때, 메모리 상에 저장된 레코드 객체의 크기는 컨슈머에 할당된 파티션별로 최대 max.partition.fetch.bytes까지 차지할 수 있음
- 주의) 브로커가 보내온 응답에 얼마나 많은 파티션이 포함되어 있는지 결정할 수 있는 방법은 없어 이 설정을 사용해 메모리 사용량을 조절하는 것은 까다로움
- 각 파티션에서 비슷한 양의 데이터를 받아 처리해야 하는 특별한 이유가 아니라면 fetch.max.bytes 설정을 대신 사용할 것을 권장!
4.5.6 session.timeout.ms와 heartbeat.interval.ms
- session.timeout.ms (default : 45s) / 참고) KIP-735
- 컨슈머가 브로커에게 하트비트를 보내지 않고도 살아 있는 것으로 판정되는 최대 시간 (=컨슈머가 하트비트를 보내지 않을 수 있는 최대 시간)
- 컨슈머가 그룹 코디네이터에게 하트비트를 보내지 않은 채로 해당 설정 시간이 지나면?
- 그룹 코디네이터는 해당 컨슈머가 죽은 것으로 간주함
- 해당 컨슈머에게 할당되어 있던 파티션들을 다른 컨슈머에게 할당하기 위해 리밸런스 실행함
- 고려할 점
- 기본값보다 낮춰 설정할 때 : 죽은 컨슈머를 빨리 찾아낼 수 있지만 원치않는 리밸런싱 초래할 수 있음
- 기본값보다 높여 설정할 때 : 비효율적인 리밸런스 가능성을 줄이지만, 죽은 컨슈머를 찾아내는 데에 시간 소요됨
- heartbeat.interval.ms
- 컨슈머가 브로커에게 하트비트를 전송하는 시간 간격
- session.timeout.ms보다 낮은 값이어야 함
4.5.7 max.poll.interval.ms
- 컨슈머가 폴링을 하지 않고도 죽은 것으로 판정되지 않을 수 있는 최대 시간 지정 (기본값 5m)
- Q. 하트비트와 세션 타임아웃이 있는데 왜 해당 설정도 필요할까?
- 하트비트는 백그라운드 스레드에 의해 전송됨
- 카프카에서 레코드를 읽어오는 메인 스레드는 데드락이 걸렸는데, 백그라운드 스레드는 멀쩡히 하트비트를 전송하고 있을 수도 있음
- 하트비트는 전송되지만 컨슈머에 할당된 파티션의 레코드들이 처리되고 있지 않음을 의미함
- 따라서 컨슈머가 여전히 레코드를 처리하고 있는지의 여부를 확인하는 가장 쉬운 방법은 컨슈머가 추가로 메시지를 요청하는지 확인하는 것!
- 참고) 해당 설정으로 인해 타임아웃이 발생하면?
- 백그라운드 스레드는 카프카 브로커가 컨슈머가 죽어서 리밸런스가 수행되어야 한다는 것을 알 수 있도록 'leave group' 요청 전송한 뒤, 하트비트 전송을 중단함
- Q. 하트비트와 세션 타임아웃이 있는데 왜 해당 설정도 필요할까?
- 해당 설정은 안전장치의 목적으로 존재함
- 요청 사이의 간격이나 추가 레코드 요청은 예측하기 힘들고 다양한 조건의 영향을 받음 (현재 사용 가능한 데이터의 양, 컨슈머가 처리하고 있는 작업의 유형, 함께 사용되는 서비스의 지연 등)
- max.poll.records를 정의했어도 poll() 호출하는 시간 간격은 예측하기 어렵기 때문임
- 따라서 해당 값은 정상 작동 중인 컨슈머가 매우 드물게 도달할 수 있을 정도로 충분히 크지만, 정지한 컨슈머로 인한 레코드 처리 지연이 길게 발생하지 않을 정도로 충분히 작게 설정되어야 함
4.5.8 default.api.timeout.ms
- API 호출 시 명시적인 타임아웃 지정하지 않는 한, 거의 모든 컨슈머 API 호출에 적용되는 타임아웃 값 (기본값 1m)
- 요청 타임아웃 기본값보다 커서 필요할 경우 이 시간 안에 재시도 가능
- 주의) poll() 메서드는 해당 값이 적용되지 않으므로, 명시적으로 타임아웃을 지정해줘야 함
4.5.9 request.timeout.ms
- 컨슈머가 브로커로부터의 응답을 기다릴 수 있는 최대 시간 (기본값 30s)
- 브로커가 지정된 시간 사이에 응답하지 않는다면?
- 클라이언트는 브로커가 완전히 응답하지 않을 것이라고 간주하고 연결을 닫은 뒤 재연결 시도함
- 브로커가 지정된 시간 사이에 응답하지 않는다면?
- 주의) 기본값 30초 보다 더 내리지 않는 것을 권장함
- 연결을 끊기 전 브로커에 요청을 처리할 시간을 충분히 주는 게 중요함
- 이미 과부하가 걸려 있는 브로커에 요청을 다시 보내거나 연결을 끊고 다시 맺는 것이 오히려 더 큰 오버헤드를 추가하게 됨
4.5.10 auto.offset.reset
- 컨슈머가 예전에 오프셋을 커밋한 적이 없거나(컨슈머가 새로 실행될 때), 커밋한 오프셋이 유효하지 않을 때(컨슈머가 오랫동안 읽은 적이 없어 오프셋의 레코드가 이미 브로커에서 삭제된 경우) 파티션을 읽기 시작할 때의 작동 정의
- 설정값
- latest (default)
- 유효한 오프셋이 없을 때 컨슈머는 가장 최신 레코드(컨슈머가 작동하기 시작한 다음부터 쓰여진 레코드)부터 읽기 시작함
- earliest
- 유효한 오프셋이 없을 때 파티션의 맨 처음부터 모든 데이터를 읽음
- none
- 유효하지 않은 오프셋부터 읽으려 할 때 예외 발생함
- latest (default)
4.5.11 enable.auto.commit
- 컨슈머가 자동으로 오프셋을 커밋할지의 여부 결정 (기본값 true)
- 해당 값이 true일 때, auto.commit.interval.ms를 사용해 얼마나 자주 오프셋이 커밋될지 제어할 수 있음
4.5.12 partition.assignment.strategy
- PartitionAssignor 클래스는 어느 컨슈머에게 어느 파티션이 할당될지 결정하는 역할
파티션 할당 전략
1) Range
- 컨슈머가 구독하는 각 토픽의 파티션들을 연속된 그룹으로 나눠서 할당
- 특징
- 각 토픽의 파티션 수가 컨슈머 수로 깔끔하게 나눠떨어지지 않는 상황에서 앞의 컨슈머가 항상 더 많은 파티션을 할당받음 (예시 참고)
- 예시) 동일한 컨슈머 그룹에 속하는 컨슈머 C1, C2가 각각 3개의 파티션을 갖는 토픽 T1, T2를 구독했을 때
- 컨슈머 C1 : T1과 T2의 0번, 1번 파티션 할당
- 컨슈머 C2 : T1과 T2의 2번 파티션 할당
- 각 토픽이 홀수 개의 파티션을 갖는 경우 첫 번째 컨슈머는 두 번째 컨슈머보다 더 많은 파티션을 할당받게 됨
2) RoundRobin
- 모든 구독된 토픽의 모든 파티션을 순차적으로 하나씩 컨슈머에 할당
- 특징
- 컨슈머 그룹 내 모든 컨슈머들이 동일한 토픽들을 구독한다면, 모든 컨슈머들이 완전히 동일한 수(혹은 많아야 1개 차이)의 파티션을 할당받음
- 예시) 동일한 컨슈머 그룹에 속하는 컨슈머 C1, C2가 각각 3개의 파티션을 갖는 토픽 T1, T2를 구독했을 때
- 컨슈머 C1 : T1의 0번, 2번 / T2의 1번 파티션 할당
- 컨슈머 C2 : T1의 1번 / T2의 0번, 2번 파티션 할당
3) Sticky
- 해당 할당자는 2가지 목표를 가지고 있음
- 파티션들을 가능한 균등하게 할당하는 것
- 리밸런스가 발생했을 때 가능하면 많은 파티션들이 같은 컨슈머에 할당되도록 하여 할당된 파티션을 다른 컨슈머로 옮길 때 발생하는 오버헤드 최소화하는 것
- 특징
- 같은 그룹에 속한 컨슈머들이 모두 동일한 토픽을 구독할 때 얼마나 균형있게 파티션이 할당되는지는 RoundRobin 방식과 크게 다르지 않지만, 이후 재할당으로 이동하는 파티션의 수 측면에서는 Sticky 방식이 더 적음
4) Cooperative Sticky
- Sticky 방식과 기본적으로 동일하지만, 협력적 리밸런스 기능을 지원함 (재할당 대상이 아닌 파티션은 담당 컨슈머가 계속해서 처리할 수 있도록 해줌)
4.5.13 client.id
- 카프카 브로커가 자신에게 요청(읽기 요청 등)을 보낸 클라이언트를 식별하기 위해 쓰임
- 로깅, 모니터링 지표, 쿼터에서도 사용됨
4.5.14 client.rack
- 클라이언트(여기서는 컨슈머)가 위치한 영역 식별자
- 2.4.0 이후 버전부터 지원
- 용도
- 기본적으로, 컨슈머는 각 파티션의 리더 레플리카로부터 메시지를 읽어옴
- 카프카 클러스터가 다수의 데이터센터 or 다수의 클라우드 가용 영역에 걸쳐 설치되어 있는 경우 컨슈머와 같은 영역에 있는 레플리카로부터 메시지를 읽어오는 것이 성능, 비용 면에서 유리함
- 가장 가까운 레플리카로부터 읽어올 수 있게 하기위해 client.rack을 설정하여 클라이언트가 위치한 영역을 식별할 수 있게 해줘야 함 cf) KIP-392
- 브로커의 replica.selector.class 설정 기본값을 org.apache.kafka.common.replica.RackAwareReplicaSelector로 설정해줘야 함
- 같은 broker.rack 설정값을 가진 브로커에 저장된 레플리카를 우선적으로 읽어옴
4.5.15 group.instance.id
- 컨슈머에 정적 그룹 멤버십 기능을 적용하기 위해 사용되는 설정
4.5.16 receive.buffer.bytes, send.buffer.bytes
- 데이터를 읽거나 쓸 때 소켓이 사용하는 TCP의 수신 및 송신 버퍼의 크기 결정
- -1로 설정 시 OS의 기본값 사용
- 다른 데이터센터에 있는 브로커와 통신하는 프로듀서나 컨슈머의 경우 이 값을 올려 잡아 주는게 좋음
- 이러한 네트워크 회선은 지연은 크고 대역폭은 낮기 때문임
Q. 네트워크 회선의 특징와 해당 설정이 어떤 연관이 있을까?
더보기특징
- 지연(latency)이 크다
- 데이터 패킷이 송신지에서 수신지까지 가는 데 시간이 오래 걸림
- 패킷을 보낼 때마다 응답을 받기까지의 시간이 길어져, 왕복 시간이 증가함
- 대역폭(bandwidth)이 낮다
- 초당 전송할 수 있는 데이터량이 적음
- 한 번에 보낼 수 있는 데이터의 크기가 제한적이라 자주 전송해야 함
연관성
- TCP 버퍼 크기가 작으면?
- 작은 크기의 데이터를 여러 번 보내야 하므로, 왕복 시간이 긴 네트워크 환경에서 비효율적
- TCP 버퍼 크기를 키우면?
- 한 번에 더 많은 데이터를 송수신하여 네트워크 왕복 횟수를 줄일 수 있음
- TCP 패킷을 묶어서 전송하는 효과
- 한 번에 더 많은 데이터를 송수신하여 네트워크 왕복 횟수를 줄일 수 있음
- 즉, 네트워크 지연이 크고 대역폭이 낮은 환경에서는 한 번에 더 많은 데이터를 송수신할 수 있도록 하기 위해 TCP 버퍼 크기를 늘리는 것이 성능 향상에 도움이 된다.
추가) offsets.retention.minutes
- 카프카 브로커의 설정이지만, 컨슈머 작동에 큰 영향을 미침
- 일반적으로 컨슈머 그룹에 현재 동작중인 컨슈머(즉, 하트비트를 보내 멤버십을 유지하고 있는 멤버)들이 있는 한, 컨슈머 그룹이 각 파티션에 대해 커밋한 마지막 오프셋 값은 카프카에 의해 보존되므로, 재할당이 발생하거나 재시작 한 경우에도 가져다 쓸 수 있음
- 하지만 그룹이 비게 된다면, 카프카는 커밋된 오프셋을 해당 설정값에 지정된 시간 동안만 보관함 (기본값 7일)
- 커밋된 오프셋이 삭제된 상태에서 그룹이 다시 활동을 시작하면 과거 읽기 작업 기록이 없기 때문에 새로운 컨슈머 그룹인 것처럼 작동하게 됨
살펴보기
'Study > 카프카 핵심 가이드' 카테고리의 다른 글
[카프카 핵심 가이드] CH6. 카프카 내부 메커니즘 (0) 2025.02.19 [카프카 핵심 가이드] CH4. 카프카 컨슈머: 카프카에서 데이터 읽기 (2) (1) 2025.02.13 [카프카 핵심 가이드] 추가 - 카프카 컨슈머 리밸런스 (0) 2025.02.11 [카프카 핵심 가이드] 3.6 파티셔너 (카프카 3.9 버전 반영) (0) 2025.02.06 [카프카 핵심 가이드] CH3. 카프카 프로듀서: 카프카에 메시지 쓰기 (0) 2025.02.04