-
[카프카 핵심 가이드] CH6. 카프카 내부 메커니즘Study/카프카 핵심 가이드 2025. 2. 19. 00:12
✅ 주요 내용
- 카프카 컨트롤러
- 카프카에서 복제(replication)가 작동하는 방식
- 카프카가 프로듀서와 컨슈머의 요청을 처리하는 방식
- 카프카가 저장을 처리하는 방식 (파일 형식, 인덱스 등)
6.1 클러스터 멤버십
- 카프카는 현재 클러스터의 멤버인 브로커들의 목록을 유지하기 위해 아파치 주키퍼를 사용함
- 각 브로커는 고유한 식별자를 갖음(브로커 설정 파일에 정의하거나 자동으로 생성)
- 주키퍼의 브로커 관리 방식
- 브로커 프로세스는 시작될 때마다 주키퍼에 Ephemeral(휘발성) 노드의 형태로 ID를 등록함
- 카프카 브로커들과 다른 툴들은 브로커가 등록되는 주키퍼의 /brokers/ids 경로를 구독해 브로커가 추가/제거되었을 때 알림 수신
- 동일한 ID를 가진 다른 브로커 시작 시 에러 발생
- 브로커와 주키퍼 간 연결이 끊어질 경우 브로커가 시작될 때 생성한 Ephemeral 노드는 자동으로 주키퍼에서 삭제됨
- 브로커가 정지하면 브로커를 나타내는 ZNode(주키퍼의 데이터 노드)는 삭제되지만, 브로커 ID는 다른 자료구조에 남아있음
- ex) 각 토픽의 레플리카 목록에는 해당 레플리카를 저장하는 브로커 ID 포함됨
- 만약 특정 브로커가 완전히 유실된 후 동일한 ID를 가진 새로운 브로커가 투입될 경우, 곧바로 클러스터에서 유실된 브로커의 자리를 대신해 이전 브로커의 토픽과 파티션들을 할당받음
- ex) 각 토픽의 레플리카 목록에는 해당 레플리카를 저장하는 브로커 ID 포함됨
- 브로커 프로세스는 시작될 때마다 주키퍼에 Ephemeral(휘발성) 노드의 형태로 ID를 등록함
6.2 컨트롤러
- 일반적인 카프카 브로커 기능에 더해서 파티션 리더를 선출하는 역할을 추가로 수행
최초 선정 방식 (클러스터 내 무조건 1개)
- 클러스터에서 가장 먼저 시작되는 브로커는 주키퍼의 /controller에 Ephemeral 노드를 생성하여 컨트롤러가 됨
- 다른 브로커 역시 시작할 때 해당 위치에 노드를 생성하려 시도하지만, '노드가 이미 존재함' 예외를 받게 됨
- 브로커들은 주키퍼의 컨트롤러 노드에 변동이 생겼을 때 알림을 받기 위해 와치(Watch)를 설정함
- 이를 통해 클러스터 안에 한 번에 단 1개의 컨트롤러만 있도록 보장함
재선정 방식
- 컨트롤러 브로커가 멈추거나 주키퍼와의 연결이 끊어질 경우, 해당 Ephemeral 노드는 삭제됨
- ex) 컨트롤러가 사용하는 주키퍼 클라이언트가 zookeeper.session.timeout.ms에 설정된 값보다 더 오랫동안 주키퍼에 하트비트를 전송하지 않았을 때
- Ephemeral 노드가 삭제되면, 클러스터 내 다른 브로커들은 주키퍼에 설정된 와치를 통해 컨트롤러가 없어졌다는 것을 알아차리게 되고 주키퍼에 컨트롤러 노드 생성 시도를 함
- 주키퍼에 가장 먼저 새로운 노드 생성을 성공한 브로커가 다음 컨트롤러가 되며, 다른 브로커들은 '노드가 이미 존재함' 예외를 받고 새 컨트롤러 노드에 대한 와치 다시 생성함
- 추가) 이전 컨트롤러에 의한 동작 무시하는 방법
- 브로커는 새로운 컨트롤러가 선출될 때마다 주키퍼의 조건적 증가 연산에 의해 증가된 에포크(epoch) 값('세대' 값)을 전달받음
- 브로커는 현재 컨트롤러의 에포크 값을 알고 있어, 만약 더 낮은 (즉, 예전) 에포크 값을 가진 컨트롤러로부터 메시지를 받은 경우 무시함
- 상황)
- 컨트롤러 브로커가 오랫동안 GC 때문에 멈춘 사이 주키퍼 사이의 연결이 끊어질 수 있음(그 사이에 새 컨트롤러가 선출될 수 있음)
- 이전 컨트롤러가 작업을 재개할 경우, 새로운 컨트롤러가 선출되었다는 것을 알지 못한 채 브로커에 메시지를 보낼 수 있음. 이러한 컨트롤러를 '좀비'라고 부름
- 컨트롤러가 전송하는 메시지에 컨트롤러 에포크를 포함하면 브로커는 예전 컨트롤러가 보내온 메시지를 무시할 수 있음
상황별 동작
- 브로커가 컨트롤러가 되었을 때
- 클러스터 메타데이터 관리와 파티션 리더 선출을 시작하기 전에 먼저 주키퍼로부터 최신 레플리카 상태 맵을 읽어옴
- 이 적재 작업은 비동기 API를 사용해 수행되고, 지연을 줄이기 위해 읽기 요청을 여러 단계로 나눠서 주키퍼로 전송함
- 파티션 수가 매우 많은 클러스터에서는 적재 작업이 몇 초씩 걸릴 수도 있음
- 참고) https://www.confluent.io/blog/apache-kafka-supports-200k-partitions-per-cluster/
- 클러스터 메타데이터 관리와 파티션 리더 선출을 시작하기 전에 먼저 주키퍼로부터 최신 레플리카 상태 맵을 읽어옴
- 브로커가 클러스터를 나갔다는 사실을 알았을 때
- 컨트롤러는 해당 브로커가 리더를 맡고 있었던 모든 파티션에 대해 새로운 브로커를 할당해줌
- 새로운 리더가 필요한 모든 파티션을 순회하며 새로운 리더가 될 브로커를 결정함 (단순히 해당 파티션의 레플리카 목록에서 바로 다음 레플리카가 새 브로커가 됨)
- 그 후 새로운 상태를 주키퍼에 쓴 뒤(지연을 줄이기 위해 요청을 여러 개로 나눠 비동기 방식으로 전송), 새로 리더가 할당된 파티션의 레플리카를 포함하는 모든 브로커에 LeaderAndISR 요청 전송함
- 요청에는 해당 파티션들에 대한 새로운 리더와 팔로워 정보 포함
- 효율성을 위해 요청들은 배치 단위로 묶어서 전송됨
- 즉, 각각의 요청은 동일한 브로커에 레플리카가 존재하는 다수의 파티션에 대한 새 리더십 정보를 포함하게 되는 것
- 컨트롤러는 모든 브로커에 리더십 변경 정보를 포함하는 UpdateMetadata 요청을 보내 각각의 캐시를 업데이트함
- 새로 리더가 된 브로커는 클라이언트로부터의 쓰기/읽기 요청을 처리하기 시작, 팔로워들은 새 리더로부터 메시지 복제 시작
- 클러스터 안의 모든 브로커는 클러스터 내 전체 브로커와 레플리카 맵을 포함하는 MetadataCache를 가지고 있기 때문에 캐시 업데이트 필요
- 컨트롤러는 해당 브로커가 리더를 맡고 있었던 모든 파티션에 대해 새로운 브로커를 할당해줌
요약하자면,
- 컨트롤러는 브로커가 클러스터에 추가되거나 삭제될 때 대상 파티션에 대한 파티션 리더를 선출할 책임을 가짐
- 컨트롤러는 스플릿 브레인(=서로 다른 2개의 브로커가 자신이 현재 컨트롤러라고 생각하는 것) 현상을 방지하기 위해 에포크 번호 사용함
6.2.1 KRaft: 카프카의 새로운 래프트 기반 컨트롤러
KRaft 등장 배경
- Kafka 3.3부터 KRaft 기능을 정식으로 사용 가능해짐
- 기존 주키퍼 기반 컨트롤러 모델이 우리가 카프카에 필요로 하는 파티션 수까지의 확장을 지원할 수 없다는 사실이 명백해짐 (파티션 수 증가 시 성능 병목 발생)
- 기존 방식(주키퍼 기반 컨트롤러)의 주요 단점
- 브로커, 컨트롤러, 주키퍼 간 메타데이터 불일치가 발생할 수 있다.
- 컨트롤러가 주키퍼에 메타데이터를 쓰는 작업은 동기적으로 수행, 브로커 메시지를 보내는 작업은 비동기적으로 수행, 주키퍼로부터 업데이트를 받는 과정 역시 비동기적으로 수행
- 이러한 동작 방식의 차이로 메타데이터 불일치 발생할 수 있음
- 파티션과 브로커의 수가 증가함에 따라 컨트롤러 재시작 시 많은 시간이 소요된다.
- 컨트롤러가 재시작될 때마다 주키퍼로부터 모든 브로커와 파티션에 대한 메타데이터를 읽어와야 하고, 이후 메타데이터를 모든 브로커로 전송함
- 메타데이터의 소유권이 나눠져있다.
- 어떤 작업은 컨트롤러가, 다른 건 브로커가, 나머지는 주키퍼가 직접 함
- 주키퍼, 카프카에 대한 학습이 필요하다.
- 주키퍼는 그 자체로 분산 시스템이기 때문에 카프카와 마찬가지로 운영을 위해 학습 필요함
- 브로커, 컨트롤러, 주키퍼 간 메타데이터 불일치가 발생할 수 있다.
- 추가) 교체되어야 할 기능
- 현재 아키텍처에서 주키퍼는 2가지 중요한 기능을 맡고 있음
- 컨트롤러 선출
- 클러스터 메타데이터(현재 운영중인 브로커, 설정, 토픽, 파티션, 레플리카 관련 정보) 저장
- 컨트롤러 그 자체가 관리하는 메타데이터도 존재
- 현재 아키텍처에서 주키퍼는 2가지 중요한 기능을 맡고 있음
Raft 기반 컨트롤러 설계의 핵심 아이디어
- 카프카 자체에 상태를 이벤트 스트림으로 나타낼 수 있도록 하는 로그 기반 아키텍처를 도입하는 것
- 장점
- 다수의 컨슈머를 사용해 이벤트를 replay하여 최신 상태를 빠르게 따라잡을 수 있음
- 로그는 이벤트 사이에 명확한 순서를 부여하고, 컨슈머들이 항상 하나의 타임라인을 따라 움직이도록 보장함
- 카프카 메타데이터를 관리하는 데에도 용이함
- 새로운 아키텍처에서 컨트롤러 노드들은 메타데이터 이벤트 로그를 관리하는 Raft 쿼럼이 됨
- 이 로그는 클러스터 메타데이터의 변경 내역을 저장함
- 현재 주키퍼에 저장되어 있는 모든 정보들(토픽, 파티션, ISR, 설정 등)이 여기에 저장됨
- 다수의 컨슈머를 사용해 이벤트를 replay하여 최신 상태를 빠르게 따라잡을 수 있음
KRaft 특징
- 자체적으로 리더 선출 가능
- Raft 알고리즘을 사용하여 컨트롤러 노드들은 외부 시스템에 의존하지 않고 자체적으로 리더를 선출할 수 있게 됨
- 새로운 컨트롤러의 메타데이터 적재 작업 소요 시간 감소
- 메타데이터 로그의 리더 역할을 맡고 있는 컨트롤러를 액티브 컨트롤러라고 부름
- 액티브 컨트롤러는 브로커가 보내온 모든 RPC 호출을 처리함
- 팔로워 컨트롤러들은 액티브 컨트롤러에 쓰여진 데이터들을 복제하고, 액티브 컨트롤러에 장애가 발생했을 시 즉시 투입될 수 있도록 준비 상태를 유지함
- 이제 컨트롤러들이 모두 최신 상태를 가지고 있으므로, 컨트롤러 장애 복구는 모든 상태를 새 컨트롤러로 이전하는 긴 리로드 시간을 필요로 하지 않음
- 메타데이터 로그의 리더 역할을 맡고 있는 컨트롤러를 액티브 컨트롤러라고 부름
- 팔로워 컨트롤러의 메타데이터 업데이트 시 pull 방식 사용
- 컨트롤러는 다른 브로커에 변경 사항을 밀어넣지 않음
- 대신, 다른 브로커들이 새로 도입된 MetadataFetch API를 사용해 액티브 컨트롤러로부터 변경 사항을 당겨옴
- 컨슈머의 읽기 요청과 유사하게, 브로커는 마지막으로 가져온 메타데이터 변경 사항의 오프셋을 추적하고 그보다 나중 업데이트만 컨트롤러에 요청함
- 브로커는 추후 시동 시간을 줄이기 위해 메타데이터를 디스크에 저장함
- 브로커 프로세스 시작 시 주키퍼가 아닌, 컨트롤러 쿼럼에 등록
- 운영자가 등록을 해제하지 않는 한 이를 유지함
- 브로커가 종료되면, 오프라인 상태로 들어가는 것일 뿐 등록은 여전히 유지됨
- 온라인 상태지만 최신 메타데이터로 최신 상태를 유지하고 있지는 않은 브로커의 경우 펜스된 상태(fenced state)가 되어 클라이언트 요청을 처리할 수 없음
참고)
- KRaft 도입 이전
- 주키퍼 프로세스
- 카프카 클러스터의 동적 메타데이터를 저장하는 역할
- 홀수 개의 프로세스가 하나의 쿼럼을 구성하며, 저장된 데이터의 업데이트 작업을 담당하는 리더 프로세스가 하나 존재
- 카프카 프로세스 (브로커 단위)
- 카프카 데이터를 저장하는 역할
- 이들 중 리더 파티션을 결정하는 역할을 하는 프로세스를 컨트롤러라고 명칭
- 주키퍼 프로세스
- KRaft 도입 이후
- 주키퍼 프로세스가 제거되어 카프카 프로세스만 존재
- 카프카 프로세스는 다음 두 개 중 적어도 하나의 역할을 가짐 (즉, 두 역할을 겸할 수도 있음)
- 컨트롤러
- 카프카 클러스터의 동적 메타데이터를 저장하는 역할
- 1개 이상의 프로세스가 하나의 쿼럼을 구성하며, 이들 중 저장된 데이터의 업데이트 및 조회 작업을 담당하는 프로세스를 액티브 컨트롤러라고 명칭
- 브로커 (카프카 브로커 자체가 아닌 카프카 프로세스가 맡을 수 있는 역할 의미)
- 카프카 데이터를 저장하는 역할
- 하나의 컨트롤러 쿼럼을 사용하는 브로커들이 모여 하나의 클러스터를 이룸
- 컨트롤러
- 용어 차이
- 브로커
- KRaft 도입 이전 : 카프카 프로세스와 동의어 (1개의 브로커 == 1개의 카프카 프로세스)
- KRaft 도입 이후 : 카프카 프로세스가 맡을 수 있는 특정한 '역할'을 의미하는 용어
- 컨트롤러
- KRaft 도입 이전 : 브로커 중에서 파티션 리더를 결정하는 역할을 맡는 특별한 브로커
- KRaft 도입 이후 : 동적 메타데이터 저장하는 역할을 하는 카프카 프로세스 (주키퍼 역할 대체)
- 브로커
6.3 복제
- 복제는 카프카의 신뢰성과 지속성을 보장하는 방식으로써 카프카 아키텍처의 핵심
- 장애는 언제든 발생할 수 있음
- 카프카에 저장되는 데이터는 토픽 단위로 조직화 됨. 각 토픽은 1개 이상의 파티션으로 분할되고, 각 파티션은 다수의 레플리카를 가질 수 있음. 각각의 레플리카는 서로 다른 브로커에 저장됨
레플리카 종류
- 리더 레플리카
- 각 파티션에는 리더 역할을 하는 레플리카가 하나씩 존재
- 일관성을 보장하기 위해, 모든 쓰기 요청은 리더 레플리카가 처리함 ⭐️
- 클라이언트들을 리더 레플리카나 팔로워로부터 레코드를 읽어올 수 있음
- 팔로워 레플리카
- 파티션에 속한 모든 레플리카 중 리더 레플리카를 제외한 나머지
- 별도 설정을 하지 않는 한, 팔로워는 클라이언트의 요청을 처리할 수 없음
- 주된 일은 리더 레플리카로 들어온 최근 메시지들을 복제하여 최신 상태를 유지하는 것
- 해당 파티션의 리더 레플리카에 크래쉬가 날 경우, 팔로워 레플리카 중 하나가 파티션의 새로운 리더 파티션으로 승격됨
Q. 팔로워 레플리카로부터 레코드를 읽으려면?
- 해당 기능의 주 목표는 클라이언트가 리더 레플리카 대신 자신과 가장 가까이에 있는 인-싱크 레플리카로부터 읽을 수 있게 하여 네트워크 트래픽 비용을 줄이는 것
- 이 기능을 사용하려면 아래 2가지 설정 필요
- 카프카 컨슈머
- 컨슈머의 위치를 지정하는 client.rack 설정
- cf) https://fordevelop.tistory.com/242#4.5.14-client.rack
- 카프카 브로커
- replica.selector.class 설정
- 해당 설정의 기본값은 LeaderSelector(항상 리더로부터 읽음)이지만, RackAwareReplicaSelector(클라이언트의 client.rack 설정값과 일치하는 rack.id 설정값을 갖는 브로커에 저장된 레플리카로부터 읽음)로 설정 가능
- 카프카 컨슈머
- 주의) 팔로워 레플리카에서 읽을 경우 컨슈머 지연을 고려해야 함
- 복제 프로토콜은 클라이언트가 팔로워 레플리카로부터 메시지를 읽어올 경우에도 커밋된 메시지만 읽도록 확장됨
- 즉, 팔로워로부터 메시지를 읽어 오더라도 이전과 동일하게 신뢰성이 보장됨
- 이를 위해 모든 레플리카는 리더가 어느 메시지까지 커밋했는지 알아야 함
- 리더는 팔로워에게 보내는 데이터에 현재의 하이 워터마크(high-water mark, 혹은 마지막으로 커밋된 오프셋) 값을 포함시켜 팔로워에게 알려줌
- 하이 워터마크 전파에는 약간의 시간이 걸리기 때문에 데이터를 읽을 때는 리더 쪽에서 읽는 것이 좀 더 빠름
- 즉, 리더 레플리카에서 읽으면 컨슈머 지연이 줄어드는 장점
- 복제 프로토콜은 클라이언트가 팔로워 레플리카로부터 메시지를 읽어올 경우에도 커밋된 메시지만 읽도록 확장됨
레플리카 동기화
- 리더 역할 레플리카(를 저장하는 브로커)가 수행하는 또 다른 일은 어느 팔로워 레플리카가 리더 레플리카의 최신 상태를 유지하고 있는지 확인하는 것
- 팔로워 레플리카(를 저장하는 브로커)는 새로운 메시지가 도착하는 즉시 리더 레플리카로부터 모든 메시지를 복제해와서 최신 상태를 유지할 수 있도록 하지만, 다양한 원인으로 동기화가 깨질 수 있음
- ex) 네트워크 혼잡으로 인해 복제 속도가 느려질 때, 브로커에 크래쉬가 발생하여 재시작했을 때
- 확인 방법
- 리더 레플리카와의 동기화 유지를 위해 팔로워 레플리카들은 리더 레플리카에 읽기 요청을 보냄
- 이 요청은 컨슈머가 메시지를 읽어오기 위해 사용하는 요청과 동일
- 리더 레플리카는 각 팔로워 레플리카가 마지막으로 요청한 오프셋 값을 확인하여 각 팔로워 레플리카가 얼마나 뒤쳐져 있는지 알 수 있음
- 리더 레플리카와의 동기화 유지를 위해 팔로워 레플리카들은 리더 레플리카에 읽기 요청을 보냄
- 팔로워 레플리카(를 저장하는 브로커)는 새로운 메시지가 도착하는 즉시 리더 레플리카로부터 모든 메시지를 복제해와서 최신 상태를 유지할 수 있도록 하지만, 다양한 원인으로 동기화가 깨질 수 있음
- 동기화 상태에 따른 구분
- out-of-sync replica
- 만약 팔로워 레플리카가 일정 시간 이상 읽기 요청을 보내지 않거나, 읽기 요청을 보내긴 했으나 가장 최근에 추가된 메시지를 따라잡지 못하는 경우 해당 레플리카는 동기화가 풀린 것으로 간주됨
- 해당 레플리카는 더 이상 장애 상황에서 리더가 될 수 없음
- replica.lag.time.max.ms 설정값으로 팔로워 레플리카가 읽기 요청을 보내지 않거나 뒤처진 상태로 있을 수 있는 일정 시간 결정
- 만약 팔로워 레플리카가 일정 시간 이상 읽기 요청을 보내지 않거나, 읽기 요청을 보내긴 했으나 가장 최근에 추가된 메시지를 따라잡지 못하는 경우 해당 레플리카는 동기화가 풀린 것으로 간주됨
- in-sync replica
- 지속적으로 최신 메시지를 요청하고 있는 레플리카
- 현재 리더에 장애가 발생할 경우 인-싱크 레플리카만이 파티션 리더로 선출될 수 있음
- out-of-sync replica
추가 - 선호 리더 (preferred leader)
- 토픽이 처음 생성되었을 때 리더 레플리카였던 레플리카를 가리킴
- 파티션이 처음 생성되던 시점에는 리더 레플리카가 모든 브로커에 걸쳐 균등하게 분포되기 때문에 '선호'라는 표현이 붙음
- 즉, 클러스터 내의 모든 파티션에 대해 선호 리더가 실제 리더가 될 경우 부하가 브로커 사이에 균등하게 분배될 것이라고 예상할 수 있음
- 카프카에는 auto.leader.rebalance.enable=true 설정이 기본적으로 되어 있음
- 선호 리더가 현재 리더가 아니지만, 현재 리더와 동기화 되고 있을 경우(in-sync replica일 때) 리더 선출을 실행하여 선호 리더를 현재 리더로 만들어줌
6.4 요청 처리
- 카프카 브로커가 하는 일의 대부분은 클라이언트, 파티션 레플리카, 컨트롤러가 파티션 리더에게 보내는 요청을 처리하는 것
- 카프카는 TCP로 전달되는 이진 프로토콜을 가지고 있고, 해당 프로토콜은 요청의 형식과 브로커가 응답하는 방식을 정의함
- 클라이언트 모두가 해당 프로토콜을 사용해 카프카 브로커와 통신함
- 언제나 클라이언트가 연결을 시작하고 요청을 전송하며, 브로커는 요청을 처리하고 클라이언트로 응답을 보냄
- 특정 클라이언트가 브로커로 전송한 모든 요청은 브로커가 받은 순서대로 처리됨
- 따라서 카프카가 저장하는 메시지는 순서가 보장되며, 카프카를 메시지 큐로 사용할 수 있는 것
카프카 프로토콜 살펴보기
- 모든 요청은 아래의 표준 헤더를 갖음
- 요청 요형 : API 키라고도 불림
- 요청 버전 : 브로커는 서로 다른 버전의 클라이언트로부터 요청을 받아 각 버전에 맞는 응답을 할 수 있음
- Correlation ID : 각 요청에 붙는 고유한 식별자. 응답이나 에러 로그에도 포함됨
- 클라이언트 ID : 요청을 보낸 어플리케이션을 식별하기 위해 사용
- 참고) https://kafka.apache.org/protocol.html
브로커 내부 요청 처리 방식
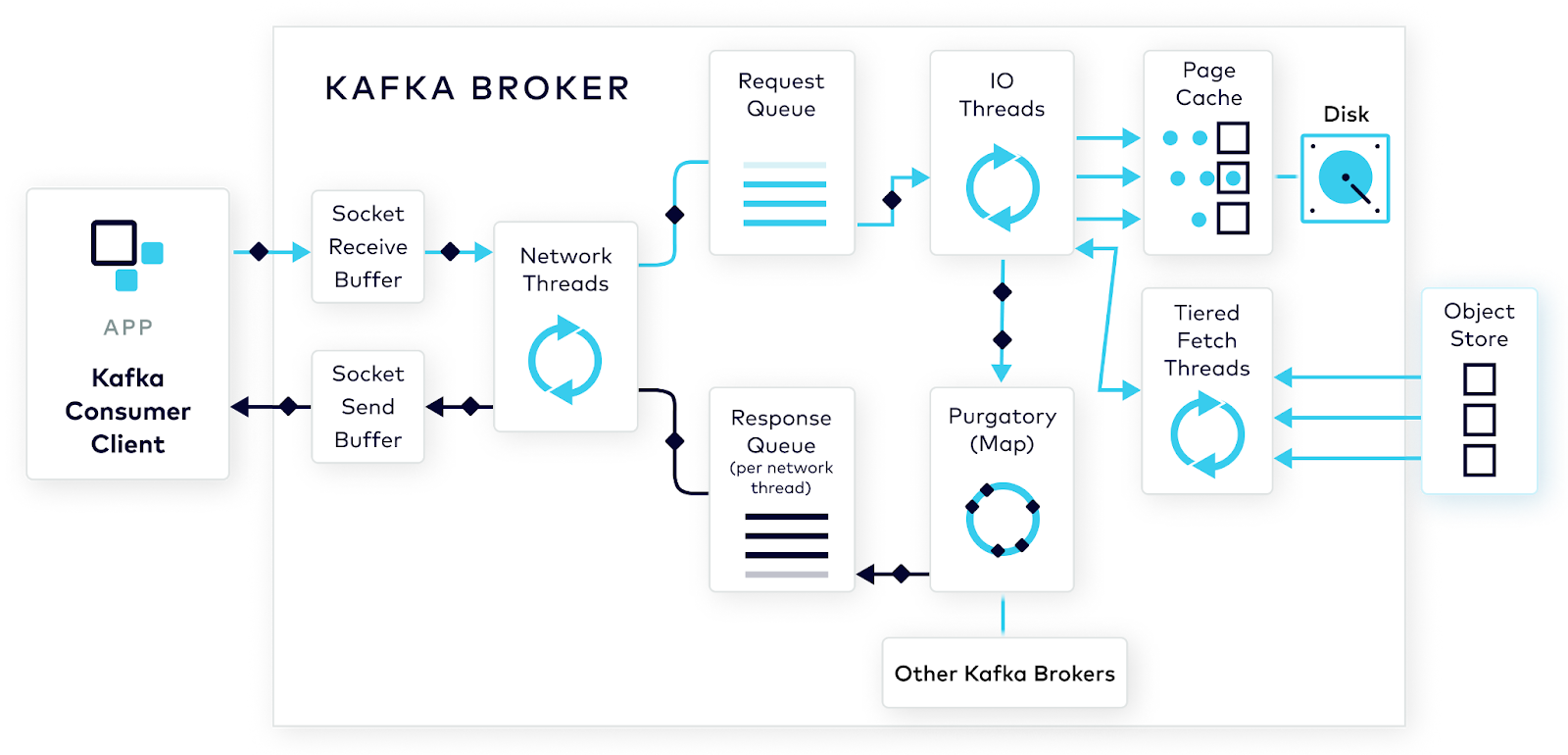
- 브로커는 연결을 받는 각 포트별로 억셉터(acceptor) 스레드를 하나씩 실행시킴
- 억셉터 스레드는 연결을 생성하고 들어온 요청을 네트워크 스레드(프로세서 스레드)에 넘김
- 네트워크 스레드 수 설정 가능
- 네트워크 스레드는 요청을 받아 요청 큐에 넣고, 응답 큐에서 응답을 가져와 클라이언트로 보냄
- 클라이언트로 보낼 응답에 지연이 필요할 때는 완료될 때까지 퍼거토리(purgatory)에 저장됨
- ex) 브로커 쪽에 데이터가 준비되었을 때만 컨슈머에게 응답 가능, 토픽 삭제가 진행중인 상황에서만 어드민 클라이언트의 DeleteTopicRequest 요청에 대한 응답 가능
- 클라이언트로 보낼 응답에 지연이 필요할 때는 완료될 때까지 퍼거토리(purgatory)에 저장됨
- 요청 큐에 요청이 들어오면, I/O 스레드(요청 핸들러 스레드)가 요청을 가져와 처리함
- 참고)
클라이언트 요청 유형
- 쓰기 요청 : 카프카 브로커로 메시지를 쓰고 있는 프로듀서가 보낸 요청
- 읽기 요청 : 카프카 브로커로부터 메시지를 읽어오고 있는 컨슈머나 팔로워 레플리카가 보낸 요청
- 어드민 요청 : 토픽 생성 및 삭제와 같이 메타데이터 작업을 수행중인 어드민 클라이언트가 보낸 요청
- 특징
- 쓰기 요청과 읽기 요청 모두 파티션의 리더 레플리카로 전송되어야 함
- 컨슈머와 브로커의 rack.id 설정 시 읽기 요청을 팔로워 레플리카에서 읽을 수도 있긴 함
- 카프카 클라이언트는 요청에 맞는 파티션의 리더를 맡고 있는 브로커에 쓰거나 읽기 요청을 전송할 책임을 짐
- 만약 브로커가 다른 브로커가 리더를 맡고 있는 파티션에 대한 읽기/쓰기 요청을 받은 경우, 클라이언트에게 'Not a Leader for Partition' 에러를 응답함
- 쓰기 요청과 읽기 요청 모두 파티션의 리더 레플리카로 전송되어야 함
Q. 클라이언트는 어디로 요청을 보내야 하는지 어떻게 알까?
- 카프카 클라이언트는 메타데이터 요청이라 불리는 또 다른 유형의 요청을 사용함
- 해당 요청은 클라이언트가 다루고자 하는 토픽들의 목록을 포함함
- 브로커는 이 토픽들에 어떤 파티션들이 있고, 각 파티션의 레플리카에는 무엇이 있고, 어떤 레플리카가 리더인지에 대한 응답을 리턴함
- 메타데이터 요청은 아무 브로커에 보내도 상관없음
- 모든 브로커들이 해당 정보를 포함하는 메타데이터 캐시를 가지고 있기 때문임
- 클라이언트는 응답으로 받은 정보를 캐싱하였다가 이를 활용해 각 파티션의 리더 역할을 맡고 있는 브로커에 바로 읽기/쓰기 요청을 보냄
- metadata.max.age.ms 설정으로 캐싱 갱신 주기 설정
- 클라이언트가 요청에 대해 'Not a Leader' 에러를 응답받은 경우 요청을 재시도하기 전에 메타데이터를 먼저 갱신함

6.4.1 쓰기 요청
- 파티션의 리더 레플리카를 가지고 있는 브로커가 해당 파티션에 대한 쓰기 요청을 받으면 몇 가지 유효성 검증을 수행함
- 데이터를 보내고 있는 사용자가 토픽에 대한 쓰기 권한을 가지고 있는가?
- 요청에 지정되어 있는 acks 설정값이 올바른가? (0, 1, "all"만 가능)
- 만약 acks 설정값이 all인 경우, 메시지를 안전하게 쓸 수 있을 만큼 충분한 in-sync 레플리카가 있는가?
- 브로커는 새 메시지들을 로컬 디스크에 씀
- 주의) 리눅스의 경우 메시지는 파일시스템 캐시에 쓰여지고, 이들이 언제 디스크에 반영될지는 보장되지 않음
- 카프카는 데이터가 디스크에 저장될 때까지 기다리지 않음
- 즉, 메시지의 지속성을 위해 복제에 의존하는 것
- 주의) 리눅스의 경우 메시지는 파일시스템 캐시에 쓰여지고, 이들이 언제 디스크에 반영될지는 보장되지 않음
- 메시지가 파티션 리더에 쓰여지고 나면, 브로커는 acks 설정에 따라 응답을 반환함
- all로 설정되어 있다면 일단 요청을 퍼거토리(purgatory) 버퍼에 저장함
- 이후 팔로워 레플리카들이 메시지를 복제한 것을 확인한 후 클라이언트에 응답 돌려보냄
- all로 설정되어 있다면 일단 요청을 퍼거토리(purgatory) 버퍼에 저장함
6.4.2 읽기 요청
- 쓰기 요청과 유사한 방식으로 읽기 요청을 처리함
- 요청을 받은 파티션 리더는 먼저 요청이 유효한지 확인함
- 지정된 오프셋이 해당 파티션에 존재하는지
- 파티션에서 삭제된 메시지나 아직 존재하지 않는 오프셋의 메시지를 요청할 경우 브로커는 에러 응답 전송
- 오프셋이 존재한다면, 브로커는 파티션으로부터 클라이언트가 요청에 지정한 크기 한도만큼의 메시지를 읽어 클라이언트에게 보냄
- 클라이언트에게 보내는 메시지에 zero-copy 최적화를 적용함
- 파일(리눅스의 파일시스템 캐시)에서 읽어 온 메시지들을 중간 버퍼를 거치지 않고 바로 네트워크 채널로 보내는 것
- 이 방식을 채택하여 데이터를 복사하고 메모리 상에 버퍼를 관리하기 위한 오버헤드가 사라지며, 결과적으로 성능 향상됨
- 클라이언트에게 보내는 메시지에 zero-copy 최적화를 적용함
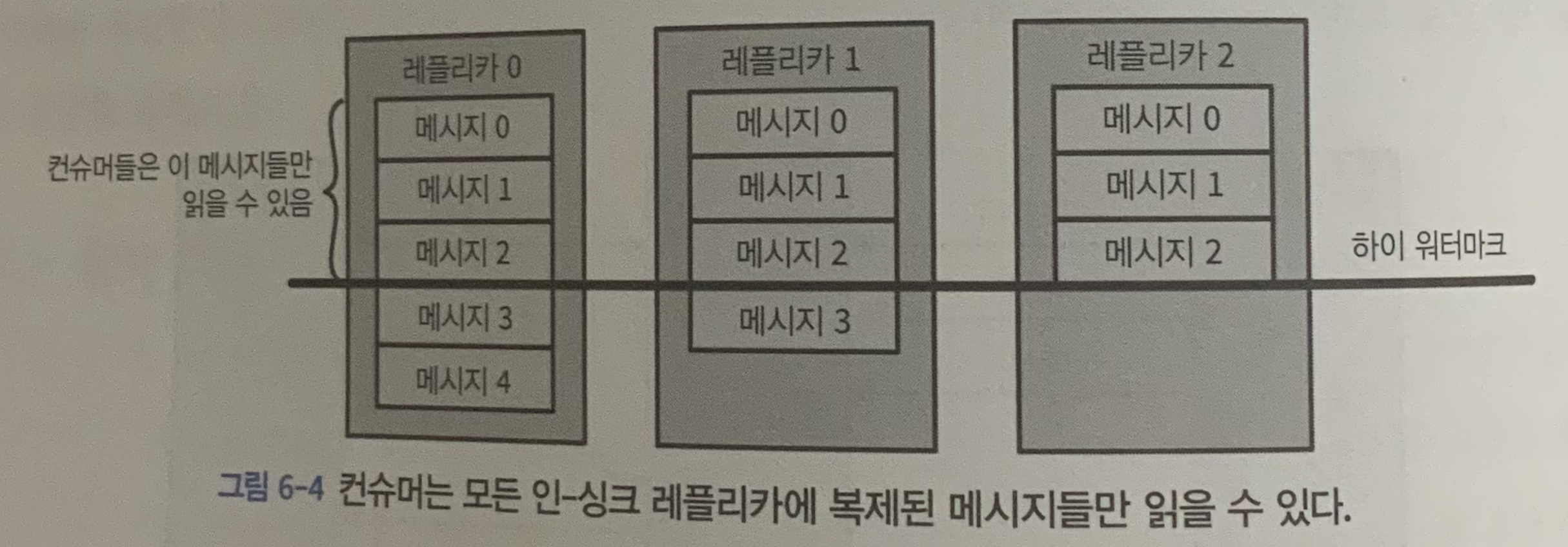
- 클라이언트는 모든 인-싱크 레플리카에 쓰여진 메시지들만 읽을 수 있음 (팔로워 레플리카도 클라이언트이긴 하지만 복제 기능을 위해 해당 룰에서는 예외)
- 파티션 리더는 어느 메시지가 어느 레플리카로 복제되었는지 알고 있으며, 특정 메시지가 모든 인-싱크 레플리카에 쓰여지기 전까지 컨슈머들이 읽을 수 없음
- 해당 메시지들을 읽으려 하면 빈 응답 리턴됨
- 파티션 리더 레플리카에 크래시가 발생한 상황에서 다른 레플리카가 파티션 리더가 되어 데이터 처리를 일관성있게 이어나가게 하기 위함
- 즉, 브로커 사이의 복제가 늦어지면, 새 메시지가 컨슈머에 도달하는 데 걸리는 시간도 길어짐
- 지연되는 시간은 replica.lag.time.max.ms 설정값에 따라 제한됨
- 이 시간 이상으로 지연되면 해당 레플리카는 out-of-sync 레플리카가 됨
- 파티션 리더는 어느 메시지가 어느 레플리카로 복제되었는지 알고 있으며, 특정 메시지가 모든 인-싱크 레플리카에 쓰여지기 전까지 컨슈머들이 읽을 수 없음
- 카프카는 읽기 세션 캐시(fetch session cache)를 사용함
- 이유)
- 컨슈머가 매우 많은 수의 파티션들로부터 이벤트를 읽어오는 경우, 요청 보낼 때마다 읽고자 하는 파티션의 전체 목록을 브로커 전송하고, 다시 브로커는 모든 메타데이터를 돌려 보냄
- 해당 값들은 잘 바뀌지 않고, 리턴해야 할 메타데이터가 그렇게 많지도 않음
- 이러한 오버헤드를 줄이기 위해 캐시 사용함
- 컨슈머가 매우 많은 수의 파티션들로부터 이벤트를 읽어오는 경우, 요청 보낼 때마다 읽고자 하는 파티션의 전체 목록을 브로커 전송하고, 다시 브로커는 모든 메타데이터를 돌려 보냄
- 세션이 한 번 생성되면, 컨슈머들은 요청을 보낼 때마다 모든 파티션을 지정할 필요 없이 점진적으로 읽기 요청만 보내면 됨
- 브로커는 변경 사항이 있는 경우에만 응답에 메타데이터를 포함하면 됨
- 세션 캐시 크기에 한도가 있기 때문에 팔로워 레플리카나 읽고 있는 파티션의 수가 많은 컨슈머를 우선시하여 어떤 경우에는 캐시된 세션이 아예 생성되지 않거나 생성되었던 것이 해제될 수 있음
- 이유)
6.4.3 기타 요청
- 카프카 브로커들 사이의 통신을 위해서도 동일한 프로토콜이 사용됨
- 이 요청들은 카프카 클러스터 내부에서 사용되는 것이므로 클라이언트에서는 사용되지 말아야 함
- ex) 파티션에 새로운 리더가 뽑힌 경우 컨트롤러가 새로운 리더와 팔로워들에게 LeaderAndIsr 요청 전송
이어서,
'Study > 카프카 핵심 가이드' 카테고리의 다른 글
[카프카 핵심 가이드] CH7. 신뢰성 있는 데이터 전달 (0) 2025.03.09 [카프카 핵심 가이드] CH6. 카프카 내부 메커니즘 - 물리적 저장소 (0) 2025.03.08 [카프카 핵심 가이드] CH4. 카프카 컨슈머: 카프카에서 데이터 읽기 (2) (1) 2025.02.13 [카프카 핵심 가이드] CH4. 카프카 컨슈머: 카프카에서 데이터 읽기 (1) (0) 2025.02.11 [카프카 핵심 가이드] 추가 - 카프카 컨슈머 리밸런스 (0) 2025.02.11