Study/카프카 핵심 가이드
[카프카] 카프카는 어떻게 고성능을 유지할까?
sw_develop
2025. 3. 24. 23:11
카프카는 디스크 기반 보존을 사용해 데이터 유실 위험을 줄인다.
그렇다면 카프카는 디스크 기반 보존을 하는데 어떻게 고성능을 유지할까?
신규 컨슈머가 추가되었을 때 이전 오프셋부터 데이터를 불러오는 경우도 있다.
이때 캐시에 데이터가 없을 수 있는데 이런 경우에도 어떻게 고성능을 낼 수 있을까?
1. append-only와 sequential write
- 카프카는 로그 형식으로 데이터를 기록하는데, 이때 append-only로 파일의 끝에 연속적으로 쓴다.
- 카프카는 파티션을 세그먼트 단위로 나누고 세그먼트는 디렉토리 내 하나의 파일 형식 - 참고
- 즉, 파일 중간을 수정하거나 임의 위치에 쓰지 않으므로, 항상 마지막에 순차적으로 write함
- 디스크에 저장할 때 가능한 연속적인 블록에 저장한다. 이를 통해 순차 I/O가 가능하다.
- 연속적인 메모리 블록에 저장하여 디스크 헤더의 seek time을 최소화할 수 있음
- OS의 read-ahead와 write-behind 기술을 통해 순차 I/O 작업이 더 빠르게 수행되도록 지원함
추가) 순차 I/O가 랜덤 I/O보다 빠른 이유
더보기
- 디스크의 쓰기/읽기 속도는 데이터를 저장할 위치를 찾거나 데이터가 저장된 위치를 찾기 위한 시간(seek time)에 의해 지연된다.
- 데이터를 순차적으로 저장할 경우 디스크 헤더를 한 번만 이동시켜 연속된 데이터를 한 번에 저장하고 읽어올 수 있다.
추가) OS의 read-ahead와 write-behind 기술
더보기
Read ahead → 읽기 성능 최적화 방식
- 필요할 것으로 예상되는 데이터를 디스크에서 미리 읽어와 캐시에 저장해두는 것
- 특정 데이터 블록 읽기를 요청했을 때 연속적인 데이터 블록들이 추후에 사용될 것으로 예상하여 미리 읽어와 캐시에 저장함 (순차 읽기할 때)
- 장점
- 순차적인 읽기나 대량의 데이터를 읽어야 할 때 읽기 성능을 향상시켜줌
- 상황
- block 1에 대한 읽기 요청
- OS는 block 1을 반환하고 추가적으로 block 2와 3을 pre-load함
- 다음 읽기로 block 2에 대한 읽기 요청을 하면 메모리에 이미 존재하기 때문에 빠른 접근이 가능함
Write behind → 쓰기 성능 최적화 방식
- 디스크에 데이터 쓰는 작업을 미루는 것
- 쓰기 요청이 발생하면 곧바로 디스크에 쓰지 않고 memory buffer(page cache)에 씀
- 백그라운드로 memory buffer(cache)에 쓴 데이터를 디스크에 쓰는 작업을 수행함
- 장점
- 프로그램 관점에서 빠른 쓰기 작업이 가능함
- 여러 개의 쓰기 요청을 배치 단위로 처리하여 디스크 쓰기 횟수를 줄임
- 빈번한 디스크 쓰기를 줄여 전체적인 시스템 성능 향상됨
- 단점
- 디스크 쓰기 전 시스템에 크래시 발생할 경우 데이터가 유실될 수 있음
- journaling이나 flush command(e.g. fsnyc()) 사용해 데이터 유실 방지할 수 있음
- 디스크 쓰기 전 시스템에 크래시 발생할 경우 데이터가 유실될 수 있음
2. page cache 활용
- 카프카는 운영체제의 Page Cache를 사용해 데이터(파일) 읽기/쓰기 성능을 향상시킨다.
- Q. Kafka는 Linux 외 다른 OS 환경에서도 동작할까?
- 기본적으로 Linux 환경에 최적화되어 있지만, 다른 OS에서도 동작은 함
- 다른 OS에서도 Page Cache는 존재하지만, 성능이나 효율성 면에서 Linux보다는 떨어짐
- Q. Kafka는 Linux 외 다른 OS 환경에서도 동작할까?
- 모든 데이터(파일) 읽기/쓰기 작업은 OS의 page cache를 거친다.
- 읽기
- 디스크에서 읽어온 데이터를 Page Cache에 저장해둠
- 이후 동일한 데이터 요청 시 디스크 접근 없이 Page Cache 조회 후 반환함
- 쓰기
- 데이터가 디스크에 바로 쓰여지지 않고 Page Cache에 먼저 쓰여짐
- 읽기

- 프로듀서가 전송한 메시지를 JVM 힙에 저장하지 않고 OS의 page cache에 저장한다.
- JVM 힙 메모리에 저장하지 않음으로써 메시지가 힙 영역을 차지하는 것을 방지할 수 있음 (GC 수행 방지)
- OS의 page cache를 사용하기 때문에 OS가 캐시를 관리한다.
- 프로세스를 재시작 해도 OS의 페이지 캐시는 그대로 남아있음
- 즉, 프로세스 재시작 후 캐시를 워밍업할 필요가 없음
추가) Linux의 Page Cache란?
더보기
리눅스 커널이 디스크 I/O 성능을 높이기 위해 사용하는 메모리 캐시
- 읽기 성능 향상
- 디스크에서 읽은 파일의 내용을 메모리에 임시 저장해둠
- 다음에 같은 파일을 또 읽을 때, 디스크에 접근하지 않고 메모리에서 빠르게 제공할 수 있음
- 쓰기 성능 향상
- 데이터가 디스크에 바로 쓰여지지 않고 Page Cache에 먼저 쓰여짐
- dirty page : 쓰기 작업 후 디스크에 아직 반영되지 않은 페이지
- write() 시스템 콜을 호출하면, 데이터는 바로 디스크에 쓰여지지 않고, Page Cache에 먼저 쓰여짐
- flush 타이밍 (언제 디스크로 반영되는지)
- 커널이 자동으로 flush
- pdflush or flush-* 로 커널 스레드가 주기적으로 dirty page를 디스크에 반영함
- 유저가 직접 flush
- fsync() or sync() 호출 시 dirty page가 디스크에 강제로 반영됨
- fsync()
- 범위 : 파일 하나
- 특정 파일 디스크립터의 dirty page만 flush
- 파일 저장 시 데이터 유실 방지를 위해 주로 사용
- sync()
- 범위 : 시스템 전체
- 모든 dirty page (파일, 디바이스 등) flush
- 시스템 종료 전 모든 변경사항 반영 위해 주로 사용
- fsync()
- fsync() or sync() 호출 시 dirty page가 디스크에 강제로 반영됨
- 커널이 자동으로 flush
특징
- 커널 공간에 있음, 커널이 직접 페이지 단위로 캐시 할당/관리함
- 시스템의 사용 가능한 메모리에 따라 유동적으로 크기가 변함
- 시스템이 메모리가 부족할 때 자동으로 reclaim
- 메모리가 부족하면 캐시된 페이지들의 메모리를 해제하여 공간 확보
참고)
- 카프카의 요청 처리
- Kafka and the File System
3. zero-copy 기법 도입
- zero-copy는 디스크 또는 네트워크와 같은 I/O 장치에서 데이터를 전송할 때 불필요한 데이터 복사를 최소화하여 성능을 높이는 데이터 전송 방식이다.
- 카프카에서는 디스크에 저장된 메시지를 네트워크를 통해 전송할 때 zero-copy 기법을 활용해 데이터 전송 성능을 향상시켰다.
> 일반적인 데이터 전송 방식
더보기
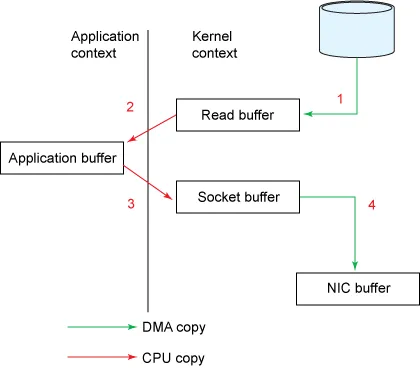
순서
- 디스크 → Read Buffer (DMA copy; Direct Memory Access)
- 유저가 read() 시스템콜 호출하면, DMA 엔진에 의해 디스크로부터 데이터를 읽어와 커널 영역의 Read Buffer에 저장함
- Read Buffer → Application Buffer (CPU copy)
- 커널 주소 공간에는 유저가 접근할 수 없으므로, Read Buffer의 내용을 Application Buffer로 복사함
- Application Buffer → Socket Buffer (CPU copy)
- 유저는 Application Buffer로 읽어들인 데이터를 Socket Buffer로 전송하기 위해 send() 함수를 호출함
- send() 함수 호출 시 커널 영역에 있는 Socket Buffer로 데이터를 복사함
- Socket Buffer → NIC Buffer (DMA copy)
- Socket Buffer에 있는 데이터를 NIC Buffer로 복사하고 네트워크를 통해 전송함
특징
- 4번의 컨텍스트 스위칭과 4개의 메모리 복사본이 생겨 불필요한 복사와 시스템콜이 발생함
- 컨텍스트 스위칭
- read() 시스템콜 호출 : 어플리케이션 스레드 → 커널 스레드
- read() 시스템콜 응답 : 커널 스레드 → 어플리케이션 스레드
- write() 시스템콜 호출 : 어플리케이션 스레드 → 커널 스레드
- write() 시스템콜 응답 : 커널 스레드 → 어플리케이션 스레드
- 메모리 복사본
- read buffer, application buffer, socket buffer, NIC buffer
- 컨텍스트 스위칭
> zero-copy 사용한 데이터 전송 방식 (리눅스 2.2 버전)
더보기
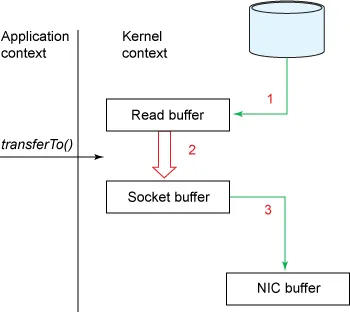
- 리눅스 2.2 버전에 소개된 sendfile() 시스템콜이 zero-copy 동작을 구현함
#include<sys/sendfile.h>
ssize_t sendfile(int out_fd, int in_fd, off_t * offset ", size_t" " count" );- 자바에서는 nio 패키지의 transferTo(), transferFrom() 메서드로 구현되어 있고, 이 메서드들 역시 sendfile() 시스템콜을 이용해 구현되어 있음
public void transferTo(long position, long count, WritableByteChannel target);
- zero-copy를 사용하면 커널 영역의 Read Buffer에서 Socket Buffer로 직접 복사(CPU copy)가 가능하여 효율적으로 데이터를 전송할 수 있다.
- 즉, read() + send() 2번의 시스템콜이 transferTo() 1번의 시스템콜 호출로 가능해짐
순서
- 유저가 transferTo() 메서드를 호출해 파일 전송 요청
- 디스크 → Read Buffer (DMA copy)
- read() 시스템콜과 동일하게, DMA 엔진이 디스크에서 파일을 읽어와 커널 주소 공간에 위치한 Read Buffer에 데이터를 복사함
- Read Buffer → Socket Buffer (CPU copy)
- 커널 모드에서 유저 모드로 컨텍스트 스위칭 없이, 바로 Socket Buffer로 데이터를 복사함
- Socket Buffer → NIC Buffer
- Socket Buffer에 복사된 데이터를 DMA 엔진을 통해 NIC Buffer로 복사함
특징
- 컨텍스트 스위칭 기존 4번 → 2번으로 줄었고, 데이터 복사본도 4개 → 3개로 줄어듦
> zero-copy 사용한 데이터 전송 방식 (리눅스 2.4 버전, CPU copy 완전 제거)
더보기
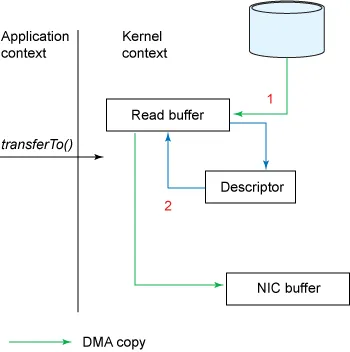
- 리눅스 2.4 이후부터 NIC(Network Interface Card) 장비가 ‘Gather Operation’을 지원할 경우 복사본을 추가로 줄일 수 있게 되었다.
순서
- 사용자가 transferTo() 메서드 호출
- 디스크 → Read Buffer (DMA copy)
- DMA 엔진이 디스크에서 파일을 읽어 커널에 위치한 Read Buffer로 데이터를 복사함
- Socket Buffer에 Descriptors 추가
- 데이터가 Socket Buffer로 복사되지 않고 대신 데이터가 저장된 위치와 데이터 사이즈에 대한 정보와 함께 디스크립터가 Socket Buffer에 추가됨
- Read Buffer → NIC Buffer (DMA copy)
- DMA 엔진은 Socket Buffer에 추가된 descriptor 내 정보를 이용해 Read Buffer에 있는 데이터를 NIC Buffer에 바로 복사(데이터 저장 위치 및 사이즈 참고하여 DMA copy 수행)하고, 네트워크로 데이터를 전송함
추가) DMA copy와 CPU copy
더보기
- 누가 데이터 복사를 수행하느냐에 따른 차이
- CPU copy
- CPU가 직접 메모리에서 데이터를 읽고 쓰면서 복사
- 복사 작업을 직접 수행하므로 다른 작업 수행할 수 없음
- DMA copy
- DMA 컨트롤러가 CPU 대신 데이터를 메모리 간 복사
- CPU는 복사 작업을 지시만 하고, 복사 자체는 DMA가 수행함
- 복사 작업을 하는 동안 CPU는 다른 작업을 할 수 있음 → 성능 향상
참고)