-
[MySQL] 인덱스 > 클러스터링 인덱스Study 2025. 3. 26. 00:16
- MySQL 서버에서 클러스터링은 클러스터링 키를 사용해 테이블의 레코드를 비슷한 것들끼리 묶어서 저장하는 형태로 구현됨
- 주로 비슷한 값들을 동시에 조회하는 경우가 많다는 점에 착안한 것
- MySQL에서 클러스터링 인덱스는 InnoDB 스토리지 엔진에서만 지원함
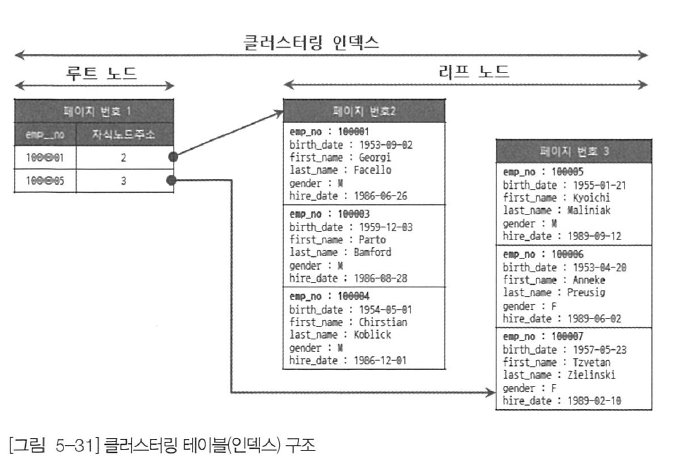
클러스터링 인덱스
- 테이블의 PK에 대해서만 적용되는 내용
- 즉, PK 값이 비슷한 레코드끼리 묶어서 저장하는 것을 '클러스터링 인덱스'라고 표현함
- 중요한 것은 PK 값에 의해 레코드의 저장 위치가 결정된다는 것
- PK 값이 변경되면 그 레코드의 물리적인 저장 위치가 바뀌어야 한다는 것을 의미하기도 함
- 인덱스 알고리즘이라기보다 테이블 레코드의 저장 방식이라고 볼 수 있음
- 클러스터링 인덱스와 클러스터링 테이블은 동의어로 사용되기도 함
- 클러스터링의 기준이 되는 PK를 '클러스터링 키'라고도 표현함
- InnoDB와 같이 항상 클러스터링 인덱스로 저장되는 테이블은 PK 기반의 검색이 매우 빠르며, 대신 레코드의 저장이나 PK의 변경이 상대적으로 느림
Q. 세컨더리 인덱스와의 차이점?
- 인덱스를 역할 기준으로 분류하면, 프라이머리 인덱스와 세컨더리 인덱스로 구분 가능
- 클러스터링 인덱스의 리프 노드에는 레코드의 모든 컬럼이 같이 저장돼 있음
- 클러스터링 테이블은 그 자체가 하나의 거대한 인덱스 구조로 관리되는 것
Q. PK가 없는 InnoDB 테이블은 어떻게 클러스터링 테이블로 구성될까? (클러스터링 키로 무엇을 사용할까)
- PK가 없는 경우 InnoDB 스토리지 엔진이 다음 우선순위대로 PK를 대체할 컬럼을 선택함
- 클러스터링 키 선택 우선순위
- PK가 있으면 기본적으로 PK를 클러스터링 키로 선택
- NOT NULL 옵션의 유닉크 인덱스(Unique Index) 중 첫 번째 인덱스를 클러스터링 키로 선택
- 자동으로 유니크한 값을 가지도록 증가되는 컬럼을 내부적으로 추가한 후, 클러스터링 키로 선택
- 적절한 클러스터링 키 후보를 찾지 못하는 경우 내부적으로 레코드의 일련번호 컬럼을 생성함
- 이렇게 자동으로 추가된 PK는 사용자에게 노출되지 않고, 쿼리 문장에서 명시적으로 사용할 수 없음
- 즉, PK나 유니크한 인덱스가 전혀 없는 InnoDB 테이블에서는 아무 의미 없는 숫자 값으로 클러스터링되는 것
세컨더리 인덱스에 미치는 영향
- InnoDB 테이블(클러스터링 테이블)의 모든 세컨더리 인덱스는 해당 레코드가 저장된 주소가 아니라 PK 값을 저장하도록 구현돼 있음
- Q. 세컨더리 인덱스가 실제 레코드가 저장된 주소를 가지고 있다면?
- 클러스터링 키에 의해 레코드의 물리적인 저장 위치가 결정되기 때문에 클러스터링 키 값이 변경될 때마다 데이터 레코드의 주소가 변경되고 그때마다 해당 테이블의 모든 인덱스에 저장된 주소값을 변경해야 함
- 이런 오버헤드를 제거하기 위해 PK 값을 저장하도록 구현돼 있음
- Q. 세컨더리 인덱스가 실제 레코드가 저장된 주소를 가지고 있다면?
Q. MyISAM이나 MEMORY 테이블은?
- MyISAM이나 MEMORY 테이블 같은 클러스터링되지 않은 테이블은 INSERT될 때 처음 저장된 공간에서 레코드가 절대 이동하지 않음
- 따라서 데이터 레코드가 저장된 주소는 내부적인 ROWID(레코드 아이디) 역할을 함
- PK나 세컨더리 인덱스의 각 키는 주소(ROWID)를 이용해 실제 데이터 레코드를 찾아옴
- MyISAM이나 MEMORY 테이블에서는 PK와 세컨더리 인덱스는 구조적으로 아무런 차이가 없음
예시)
CREATE TABLE employees( emp_no INT NOT NULL, first_name VARCHAR(20) NOT NULL, PRIMARY KEY (emp_no), INDEX ix_firstname(first_name) ); SELECT * FROM employees WHERE first_name='me';- MyISAM
- ix_firstname 인덱스를 검색해서 레코드의 주소를 확인한 후, 레코드의 주소를 이용해 최종 레코드를 가져옴
- InnoDB
- ix_firstname 인덱스를 검색해 레코드의 PK 값 확인한 후, 프라이머리 키 인덱스 검색해 최종 레코드 가져옴
- 세컨더리 인덱스 검색 --> PK 값 확인 --> 클러스터링 인덱스 검색
- ix_firstname 인덱스를 검색해 레코드의 PK 값 확인한 후, 프라이머리 키 인덱스 검색해 최종 레코드 가져옴
클러스터링 인덱스의 장점과 단점
참고)
- 일반적으로 PK를 클러스터링 키로 선정하기 때문에 아래에 나오는 PK를 '클러스터링 키'라고 생각하면 됨
- 일반적인 웹 서비스 같은 환경에서는 쓰기와 읽기 비율이 2:8 또는 1:9 정도이기 때문에 조금 느린 쓰기를 감수하고 빠른 읽기를 유지하는 것이 중요함
장점 : 빠른 읽기
- 클러스터링 키로 검색할 때 처리 성능이 매우 빠름
- 특히, 클러스터링 키로 범위 검색하는 경우 매우 빠름 (클러스터링 키 기준으로 정렬되어 저장되어 있으니까)
- 테이블의 모든 세컨더리 인덱스가 (실제 레코드의 주소가 아닌) PK를 가지고 있기 때문에 인덱스만으로 처리될 수 있는 경우가 많음
- 이를 '커버링 인덱스'라고 함
단점 : 느린 쓰기
- 테이블의 모든 세컨더리 인덱스가 클러스터링 키를 가지고 있기 때문에 클러스터링 키 값의 크기가 클 경우 전체적으로 인덱스의 크기가 커짐
- 세컨더리 인덱스를 통해 검색할 때 PK로 다시 한번 검색해야 하므로 처리 성능이 느림
- 세컨더리 인덱스는 PK를 가지고 있으므로 세컨더리 인덱스 검색 후 클러스터링 인덱스 검색해야 함
- INSERT할 때 PK에 의해 레코드의 저장 위치가 결정되기 때문에 처리 성능이 느림
- PK를 변경할 때 레코드를 DELETE하고 INSERT하는 작업이 필요하기 때문에 처리 성능이 느림
클러스터링 테이블 사용 시 주의사항
1) 클러스터링 인덱스 키의 크기
- 클러스터링 테이블의 경우 모든 세컨더리 인덱스가 클러스터링 키 값을 포함함
- 따라서 클러스터링 키의 크기가 커지면 세컨더리 인덱스도 자동으로 크기가 커짐
- 인덱스의 크기가 커질수록 같은 성능을 내기 위해 그만큼의 메모리가 더 필요해지므로 InnoDB 테이블의 클러스터링 키는 신중하게 선택해야 함
- 인덱스의 크기가 커지면 하나의 Page 내 저장 가능한 인덱스 레코드 수가 줄어들게 되어 더 많은 Page를 메모리에 올려야 하기 때문
2) PK는 AUTO-INCREMENT보다는 업무적인 컬럼으로 생성(가능한 경우)
- PK는 클러스터링 키로 사용되기 때문에 PK에 의해 레코드의 물리적인 저장 위치가 결정됨
- 즉, PK로 검색하는 경우(특히 범위로 많은 레코드를 검색하는 경우) 클러스터링되지 않은 테이블에 비해 매우 빠르게 처리될 수 있음
- 대부분 검색에서 상당히 빈번하게 사용되는 것이 일반적이므로, 컬럼의 크기가 크더라도 업무적으로 해당 레코드를 대표할 수 있다면 해당 컬럼을 PK로 설정하는 것이 좋음 (의미있는 값을 PK로 설정해 검색 시 사용하기 위함)
3) PK는 반드시 명시할 것
- 가능하면 AUTO_INCREMENT 컬럼을 이용해 PK를 생성하는 것을 권장함
- InnoDB 테이블에서 PK를 정의하지 않으면 InnoDB 스토리지 엔진이 내부적으로 일련번호 컬럼을 추가해 해당 컬럼을 클러스터링 키로 사용함 (NOT NULL 조건의 유닉크 인덱스도 존재하지 않는 경우)
- 이렇게 자동으로 추가된 컬럼을 사용자에게 보이지 않으므로 사용자가 접근할 수 없음
- 즉, InnoDB 테이블에 PK를 설정하지 않는 경우와 AUTO_INCREMENT 컬럼을 생성해 PK로 설정하는 것이 결국 똑같다는 것
- 그렇다면 사용자가 사용할 수 있는 값(AUTO_INCREMENT 값)을 PK로 설정하는 것이 오히려 낫다는 것
- 추가) ROW 기반의 복제나 InnoDB 클러스터에서는 모든 테이블이 PK를 가져야만 정상적인 복제 성능을 보장하기도 하므로 PK는 꼭 생성하자
4) AUTO-INCREMENT 컬럼을 인조 식별자로 사용할 경우
- 여러 개의 컬럼이 복합으로 PK가 만들어지는 경우 PK의 크기가 길어질 때가 있음
- PK 크기가 길어도 세컨더리 인덱스가 필요하지 않는 경우에는 그대로 PK를 사용하는 것이 좋음
- 만약, 세컨더리 인덱스도 필요하고 PK의 크기도 길다면 AUTO_INCREMENT 컬럼을 추가해 이를 PK로 설정하면 됨
- 이렇게 PK 대체를 위해 인위적으로 추가된 PK를 '인조 식별자(Surrogate key)'라고 함
- 로그 테이블 같이 조회보다 INSERT 위주의 테이블들은 AUTO_INCREMENT를 사용한 인조 식별자를 PK로 설정하는 것이 성능 향상에 도움이 됨
'Study' 카테고리의 다른 글
[MySQL] 실행 계획 > Extra 컬럼 > 커버링 인덱스 (Using Index) (0) 2025.03.26 [MySQL] 인덱스 (0) 2025.03.25 - MySQL 서버에서 클러스터링은 클러스터링 키를 사용해 테이블의 레코드를 비슷한 것들끼리 묶어서 저장하는 형태로 구현됨