Study/컴퓨터 밑바닥의 비밀
[컴퓨터 밑바닥의 비밀] 2.6 동기와 비동기
sw_develop
2025. 3. 1. 02:42
1. 동기 호출
동기 방식의 함수 호출
funcA()
{
// funcB 함수가 완료될 때까지 기다린다.
funcB();
...
}- funcA 함수가 funcB 함수를 호출하면, funcB 함수 실행이 완료될 때까지 funcA 함수의 나머지 코드는 실행되지 않음
- 즉, funcA 함수는 반드시 funcB 함수 실행이 완료될 때까지 기다려야 함
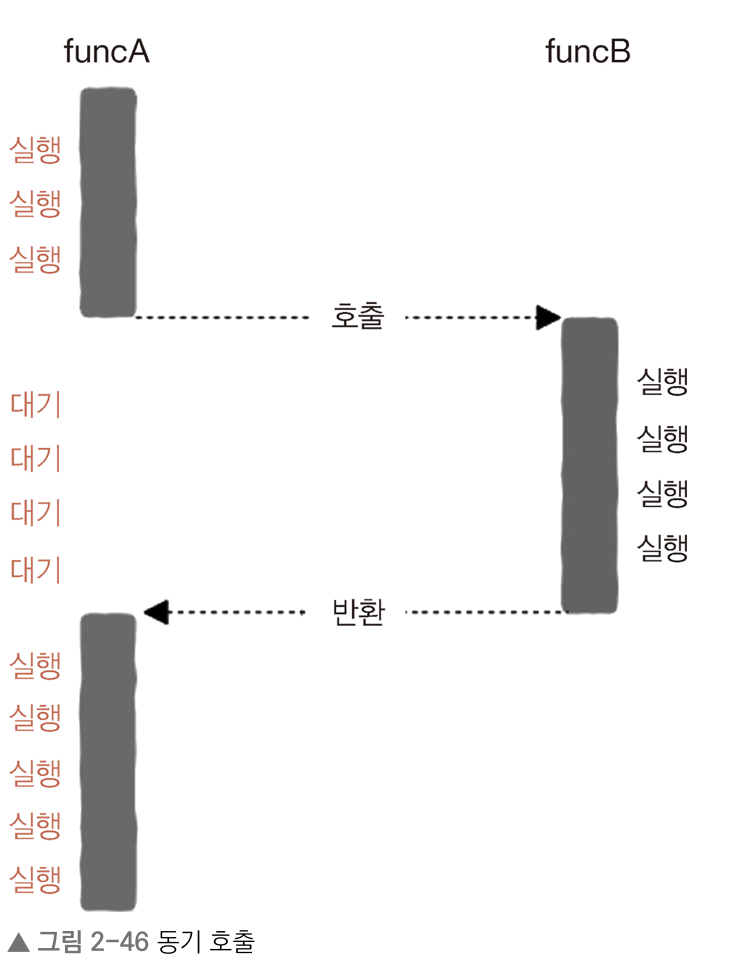
특징
- 순차적으로 진행되기 때문에 직관적이어서 이해하기 쉬움
- 일부 상황(I/O 작업 포함된 경우)에서 호출자가 요청한 작업이 끝날 때까지 기다려야 하기 때문에 효율이 높지 않음
Q. 동기 호출될 때 입출력 작업이 포함되어 있으면 어떻게 동작하는가?
예시) 입출력 작업을 할 때 다음과 같이 read 함수를 호출하여 파일을 읽는 상황
...
read(file, buf); // 여기에서 실행이 일시 중지된다.
...
// 파일 읽기가 완료될 때까지 기다렸다가 완료되면 계속 실행한다.
- 최하단 계층은 실제로 시스템 호출(system call)로 운영체제에 요청을 보냄
- 운영체제는 파일 읽기 작업을 위해 위와 같이 호출 스레드를 일시 중지시키고, 커널이 디스크 내용을 읽어 오면 일시 중지되었던 스레드가 다시 깨어남
- 위와 같이 read 함수를 동기 호출하면, 해당 함수가 반환될 때 파일 읽기 작업이 모두 완료되었음을 의미함
- 이것이 블로킹 입출력(blocking input/output)임
- 주의)
- 위 방식도 동기 호출임 (단지 호출자와 파일을 읽는 코드가 다른 스레드에서 실행되고 있을 뿐)
- 동기 호출은 호출자와 수신자가 같은 스레드에서 실행 중인지 여부와는 관련 없음
2. 비동기 호출
- 시간이 많이 걸리는 입출력 작업을 백그라운드 형태로 실행함
- 입출력 작업 : 디스크의 파일 읽고 쓰기, 네트워크 데이터 송수신, 데이터베이스 작업 등
Q. 비동기 호출될 때 입출력 작업이 포함되어 있으면 어떻게 동작하는가?
예시) 입출력 작업을 할 때 다음과 같이 read 함수를 호출하여 파일을 읽는 상황
read(file, buff); // read 함수는 즉시 반환된다.
// 이후 내용의 실행을 블로킹하지 않는다.

- 이것이 비동기 입출력임
- 호출 스레드가 블로킹되지 않고 read 함수가 즉시 반환되기 때문에 호출 스레드는 즉시 다음 작업을 실행할 수 있음
- 호출자의 이후 작업은 파일 읽기 작업과 동시에 진행되기 때문에 이것이 비동기의 높은 효율성을 가져옴
Q. 비동기 호출 방식에서 작업이 실제로 완료되는 시점을 어떻게 파악할 수 있을까?
두 가지 상황
- 호출자가 실행 결과를 전혀 신경 쓰지 않을 때
- 호출자가 실행 결과를 반드시 알아야 할 때
첫 번째 상황
- 구현 : 콜백 함수 사용
예시)
- read 함수를 비동기 호출할 때 파일 내용을 처리하는 함수를 매개변수로 함께 전달함
void handler(void* buf) {
// 파일 내용 처리
}
read(buf, handler);- 계속해서 파일을 읽고, 작업이 완료되면 전달된 함수를 사용해 파일을 처리해달라는 의미
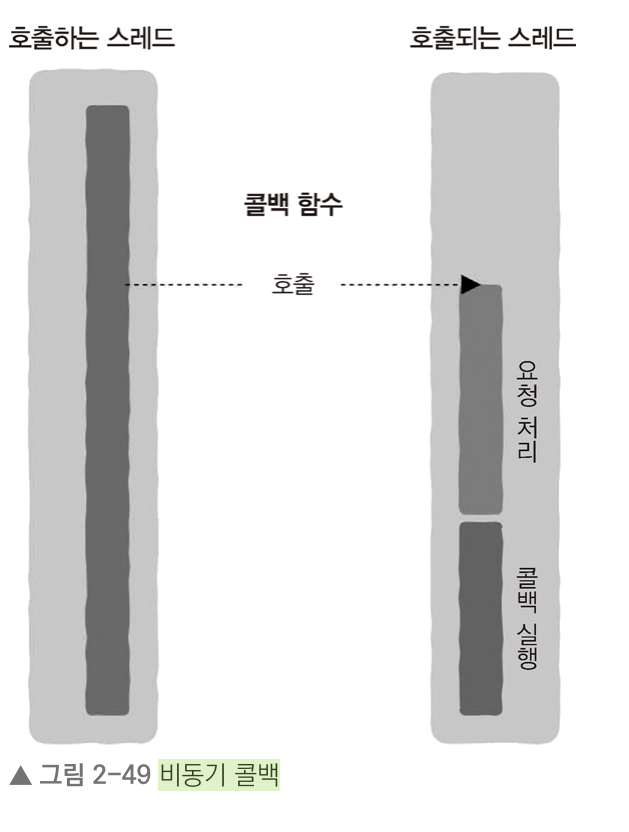
- 파일 내용은 호출자 스레드가 아닌 콜백 함수가 실행되는 다른 스레드 또는 프로세스 등에서 처리함
두 번째 상황
- 구현
- 알림 작동 방식 사용하는 것
- 작업 실행이 완료되면 호출자에게 작업 완료를 알리는 신호나 메시지 보냄

- 함수의 비동기 호출 시 일반적으로 호출자와 결과 처리는 서로 다른 스레드에서 실행됨
3. 웹 서버에서 동기와 비동기 작업
예시)
다음과 같이 사용자 요청을 처리하기 위해 A, B, C 세 단계를 거친 후 데이터베이스를 요청하고, 데이터베이스 요청 처리가 완료되면 다시 D, E, F 세 단계를 거쳐야하는 작업
A;
B;
C;
데이터베이스 요청;
D;
E;
F;- A, B, C, D, E, F에는 입출력 작업이 포함되어 있지 않음 (파일 읽기나 네트워크 통신 등 작업 X)
- 일반적으로 이런 형태의 웹 서버에는 주 스레드와 데이터베이스 처리 스레드라는 전형적인 두 개의 스레드가 존재함
동기 방식
// 메인 스레드
main_thread()
{
while(1)
{
요청 수신;
A; B; C;
데이터베이스 요청 전송하고 결과 반환될 때까지 대기;
D; E; F;
결과 반환;
}
}
// 데이터베이스 스레드
database_thread()
{
while(1)
{
요청 수신;
데이터베이스 처리;
결과 반환;
}
}
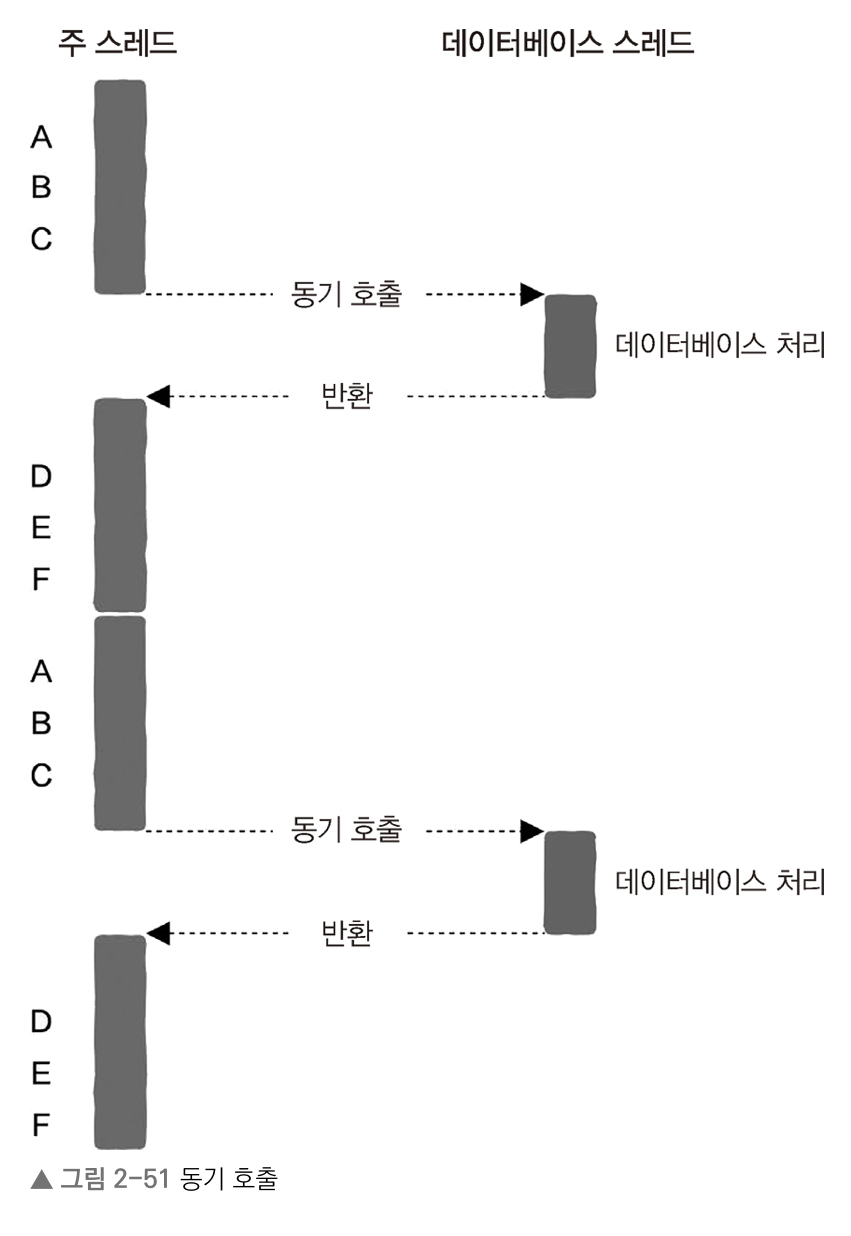
- 데이터베이스 요청 후 주 스레드가 블로킹되어 일시 중지되고, 데이터베이스 처리가 완료된 시점에서 이후 단계인 D, E, F가 실행됨
- 주 스레드 가운데의 빈 공간을 주 스레드의 '유휴 시간(idle time)' 임
- 유휴 시간 동안 데이터베이스 처리가 완료될 때까지 기다려야 다음 과정을 처리할 수 있음
비동기 방식
- 주 스레드가 데이터베이스 처리가 완료될 때까지 기다리지 않고, 데이터베이스 처리 요청을 전송하자마자 바로 다음에 넘어온 새로운 사용자 요청을 직접 처리함
Q. 위와 같이 동작할 때, 이전 요청의 나머지 D, E, F 단계는 어떻게 처리될까?
첫 번째 상황: 주 스레드가 데이터베이스 처리 결과를 전혀 신경 쓰지 않을 때
- 콜백 함수 사용
- 주 스레드가 데이터베이스 처리 요청을 보낼 때 콜백 함수를 매개변수로 전달함
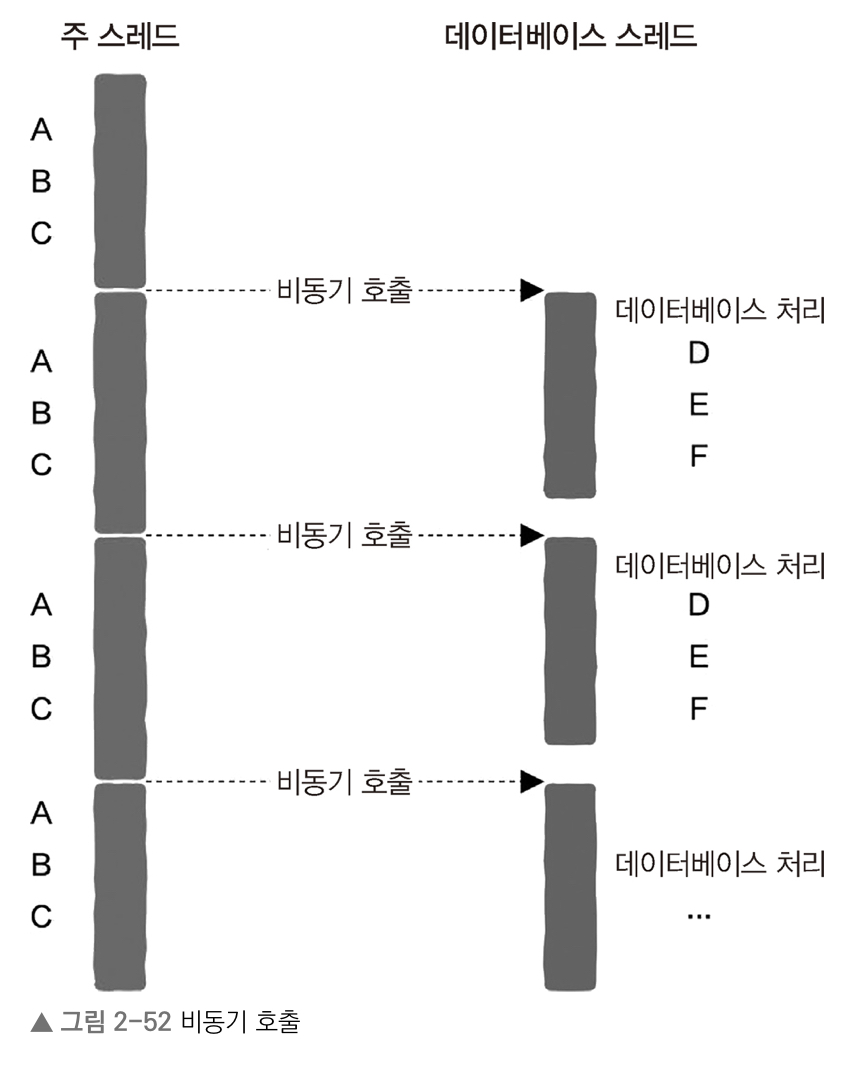
- 데이터베이스 처리가 완료된 후 주 스레드가 아닌 데이터베이스 스레드가 다음 D, E, F 세 단계를 자체적으로 직접 처리함
- 주 스레드의 '유휴 시간' 없어짐
- 주 스레드가 사용자 요청을 처리하는 작업과 데이터베이스 스레드가 데이터베이스를 처리하는 작업을 동시에 진행할 수 있음
- 시스템 리소스를 더 많이 최대한 활용할 수 있어 요청 처리 속도 증가 => 비동기가 가지는 높은 효율성
두 번째 상황: 주 스레드가 데이터베이스 작업 결과에 관심을 가질 때

- 주 스레드의 '유휴 시간' 없어짐
- 데이터베이스 스레드는 알림 작동 방식을 이용해 작업 결과를 주 스레드로 전송해야 함
- 주 스레드는 메시지를 수신하면 이전 사용자 요청의 후반부를 계속 처리함